Optimizing Jobs with Hadoop
Scheduling Jobs with the Cluster
INFO
Set here how jobs are scheduled for the Hadoop cluster to help optimize jobs and priorities.
No Impersonation
If not using impersonation, you can set the scheduling of jobs for specific cluster queues at either a global or per job level.
Global Level
- Open the "Admin" tab.
- Select "Cluster Configuration" from the side menu.
Add the following property in the "Custom Properties" section.
Queue Propertydas.job.queue=<cluster queue name>
Job Level
- Navigate through the Job Wizard when setting up or configuring a job.
- Add the properties listed above in the "Custom Properties" tab.
Example: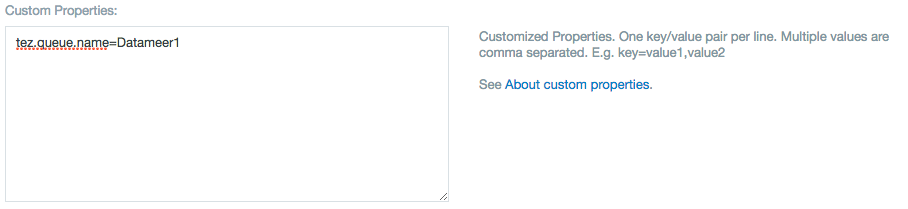
Impersonation
INFO
Datameer X users that are running impersonation don't need to set any scheduling properties in Datameer. Jobs coming from Datameer X already are labeled and all configuration for the queues are made on the Hadoop cluster itself.
Finding the Optimal Split Size/Split Count
The optimal split size and count for a Hadoop job is calculated by Hadoop from the values for max/min split size and max/min split count.
The default values are:
min/max split size: 16 MB / 5 GB min/max split count: 0 / 2147483647
For a job with an input size of 89 MB (473774773 records) Hadoop would use a split count of 5 which is approximately the minimum split size (16 MB).
Split size | Split count | Execution time |
|---|---|---|
16MB | 5 | 7m47s |
If you change the split size and split count recommendations for Hadoop to:
min/max split size: 488 kb / 5 GB min/max split count: 0 / 2147483647
Hadoop comes to the following values:
Split size | Split count | Execution time |
|---|---|---|
~ 1MB | 83 | 3m22s |
The split size has been rounded, resulting in 83 splits rather than 89. In general this looks good, but it appears that the minimum split size is a major factor for choosing the right values.
What about the map task capacity of the Hadoop cluster for this job run? The cluster used for this example has a map task capacity of 28. This means it runs a maximum of 28 jobs in parallel, therefore using only a maximum split count of 5 won't be optimal. Also using a split count of 83 returns better results, but this also creates an overhead in regards to size and map task creation/communication.
Optimization would include the reduction of tasks by utilizing all nodes in the cluster.
Lets try a split count of 28.
Split size | Split count | Execution time |
|---|---|---|
3MB | 28 | 3m8s |
Is it best to set the number of splits equal to the total map task capacity? Well, this can result in pretty large splits, which might lead to extremely long-running tasks that could then block other Hadoop tasks. Here Hadoop couldn't optimize the execution of tasks.
A better approach is to have a split count that is a multiple of the map task capacity. In this case the cluster is scaled properly, and the time a task blocks the Hadoop cluster is reduced.
inputSize / ( multiplier * mapTaskCapacity ) = splitSize
InputSize is the size of the input data for a specific job, e.g. for an import job it is the size of the data imported and for a workbook it is the size of the data resulting from an import job. The mapTaskCapacity is property used by the Hadoop cluster the job runs on. To find the optimal split size you should now calculate the splitSize value using the optimal multiplier. The multiplier can be calculated using the formula below.
multiplier = inputSize / (maxSplitSize * mapTaskCapacity), rounded up to the next whole number
Set the split size (in bytes) in the Hadoop properties section for the job.
If you calculated a split size of 3MB set it with the following commands.
mapred.max.split.size=3145728 mapred.min.split.size=3145728
Summary
- Job input data size: 89MB
- Map task capacity: 28
- Job input record count: 473774773
Split size | Split count | Execution time |
|---|---|---|
1.000.000 byte | 94 | 3m37s |
1 MB | 83 | 3m22s |
3.000.000 byte | 28 | 3m8s |
16.000.000 byte | 5 | 7m47s |
45.000.000 byte | 2 | 16m45s |
Examples
- Jop input data size: 1MB
- Map task capacity: 28
- Job input record count: 94932
Split size | Split count | Execution time |
|---|---|---|
1MB | 1 | 5m27s |
63kb | 28 | 6m14s |
21kb | 83 | 11m59s |
Logging file split resolving
In order to view the split files in the log:
- Start setting up the Import Job
- Under 'Scheduling' tab, add the line below in the text area for setting up Hadoop properties
print.resolved.splits=true