Custom Properties
- Judy Bergstresser (Deactivated)
About Custom Properties
Custom properties consist of a name (key) and value pair separated with a '='. These properties are used to configure Hadoop jobs.
DAS Properties
| Name | Default Value | Description |
|---|---|---|
| das.aggregation.map-cache-size | ByteUnit.MB.toBytes(16) | Size of Cache for Map-Side Aggregation in bytes. Less than or equal to 0 means disable Map-Side Aggregation. |
das.big-decimal.precision | 32 | During data ingestion, /wiki/spaces/DAS60/pages/4620163738 of big integer and big decimal have the maximum precision rounded to this value. |
| das.debug.job-metadata | enabled | Possible values are these from the enum JobMetaDataMode (ENABLED, DISABLED, DEFLATED) |
| das.debug.job.report-progress-interval | -1 | Interval in milliseconds a reporting thread will report progress to hadoop's tasktracker. If set to <= 0 no thread will be installed and progress is reported by mappers, reducers, readers, etc... as usual. |
| das.expression.records.max | Integer.MAX_VALUE | Maximum array size that a function may return. If this value is exceeded the excess records are chopped off. |
| das.group-series-expression.records.max | -1 | Maximum number of records a group series expression can generate. |
| das.jobconf .cache-properties | Properties like " das.plugin-registry.conf,map-runnable,reducer,mapred.input.dir" | Properties are evacuated to the distributed cache. Evacuation means, before submitting the job, the properties are stripped out of the job-conf and written into one file in the distributed cache. On a task side, before any serious work happens, the properties are read from the distributed cache and added to the job-conf. Disable the whole mechanism by setting ' das.jobconf .cache-properties' to ''. |
| das.job.map -task.memory | 2048 | |
| das.job.reduce -task.memory | 2048 | |
| das.job.app lication-manager.memory | 2048 | |
| das.job.reduce .tasks | -1 | {@link datameer.dap.sdk.util.HadoopConstants.MAPRED#REDUCE_TASKS} is calculated dynamically. If for any reason you want to enforce a specific reduce count, set this property to greater then zero. |
| das.job.reduce .tasks.correct | true | If the reducer count should be adapted based on the split-count (map-task count). |
| das.error.log.replication-factor | 2 | The replication factor for the error-logs which are getting written for dropped records. |
| das.splitting.map-wave-count | 3 | The map-wave-count to influence the number of map-task DAS uses for internal and for file-based import jobs. |
| das.splitting.map-slots.safety-factor | 1 | The number of map-slots which isn't used for the last map-wave in order to absorb node-failures. |
| das.splitting.disable-combining | false | Determines how splitting occurs. Setting the value to true ensures that a files are not split based on blocks. |
| das.splitting.disable-individual-file-splitting | false | Determines how splitting occurs for an individual file. Setting the value to true ensures that a single file isn't split based on its blocks. |
| das.splitting.max-rewind-count | 1024 * 1024 * 10 | For support of {@link MultipleSourceRecordParser}. Determines the number of bytes a middle-split is rewinded at the maximum in case the split doesn't start with a valid raw-record. |
| das.splitting.max-split-count | Datameer merges multiple small files into combined splits and splits large files into multiple smaller splits. Setting this property can control the maximum number of splits that should be created. This is good to reduce the number of file handlers due to a lack of RPC resources. | |
| das.splitting.non-splittable-encodings | UTF-16, UTF-16BE, UTF-16LE | Lists the file encodings for which splitting is restricted to only file level. For example, a file with this kind of encoding is not split at the block level. |
| das.job.concurrent-mr-jobs.new-graph-api | 5 | Only for new graph API: The maximum number of MR jobs that can run concurrently for each Datameer job. |
| das.join.deferred-file.memory-threshold | 52428800 | Maximum size of memory which is used to cache values during join before falling back to file. 50 MB default. |
| das.join.map-side.memory.max-uncompressed-file-size | 31457280 | |
| das.join.map-side.memory.max-file-size | 10485760 | |
| das.preview .generation.additional-records-ratio | 0.2f | All tasks together will try to create a preview of maxPreviewSize*the-configured-ratio in order to balance tasks with less records. |
| das.preview .group-series-expression.records.max | 100 | Maximum number of records a group series expression can generate for a preview. |
| das.join.disabled-strategies | ||
| das.range-join.map-side.max-uncompressed-file-size | 31457280 | Max uncompressed file size the file can have that we attempt to load into memory for a map-side range join. |
| das.range-join.map-side.max-records | 10000 | Max number of records the file can have that we attempt to load into memory for a map-side range join. |
| das.range-join.reduce-side.max-reducers | -1 | Max number of reducers to use for reduce-side range join implementation, -1 mean determine based on input sizing. |
| das.range-join.reduce-side.min-bytes-per-reducer | 536870912 | Minimum number of bytes each reducer should see, used by auto reducer count algorithm to help determine the number of reducers. |
| das.range-join.reduce-side.volume-weighting-factor | 0.7 | Factor to control weighting of the reducer data volume when determining the number of reducers for the reduce-side range join. |
| das.jdbc.imp ort.sql.badwords | commit, savepoint, rollback, set, checkpoint, grant, revoke, insert, update, delete, index, alter, create, lock, drop, truncate, ;, rename, comment, call, merge, explain, shutdown, show, describe, exec, go, declare | List of words that are not allowed in SQL entered by the user in SQL import. The string is broken up at the ',' and any spaces are part of the bad words. The string is parsed as a String[]. Examples of bad word sql follows: This property should be updated on the |
| das.jdbc.import.transaction-isolation | TRANSACTION_READ_COMMITTED | Sets a custom transaction isolation level for a JDBC connection to read data. Other possible values include TRANSACTION_NONE, TRANSACTION_READ_UNCOMMITED, TRANSACTION_REPEATABLE_READ, and TRANSACTION_SERIALIZABLE. |
| das.import.hidden-file-prefixes | "." | Comma separated list of file prefixes which will be used to exclude files from import. |
| das.import.hidden-file-suffixes | Comma separated list of file suffixes which will be used to exclude files from import. | |
| das.import.wizard.max-splits | 5 | The maximum number of files/splits which are retrieved by the import-job wizard in order to create import preview records. |
| das.import .ssh.default-max-mappers | 5 | Default number to use for max mappers when using the ScpProtocol for import. |
| das.import .whole-text-file.max-size | ByteUnit.MB.toBytes(4) | Max size in bytes to read when importing/uploading an HTML file. |
| das.compute.column-metrics | true | Whether or not column metrics should be computed (Column metrics are a requirement for the flipside of a sheet). |
| das.merge-sort.max-files | 200 | Maximum number of files that should be opened at once when doing a merge sort. If this number is exceeded the merge sort will happen in multiple steps. |
| das.merge-sort.max-file-size | 5242880 | Maximum file size of a file that can be included in a multi step merge sort. Files bigger than that will not be combined (5 MB). |
| das.network.proxy.type | HTTP | Proxy settings to be used for http/https outgoing connections for web service import jobs etc. das.network.proxy.type can be HTTP or SOCKS or SOCKSV4 (Socks v4) |
| das.network.proxy.host | localhost | |
| das.network.proxy.port | 3128 | |
| das.network.proxy.blacklist | localhost|127.0.0.1|192.168.*.*|*.datameer.com | To exclude hosts from connecting to through the configured proxy you can specify a blacklist of hosts, ips & masks (with * acting as a wild card). |
| das.network.proxy.username | For proxies requiring authentication, set the username. | |
| das.network.proxy.password | For proxies requiring authentication, set the password. | |
| das.tde-export.temp-location=/path | java.io.tmpdir | For controlling hard disk space for TDE files if the Datanode hard disk is limited. |
| das.job.hadoop-progress.timeout | (no default) | Sets a duration, in seconds, after which a Datameer job will terminate with a "Timed out" status if there is no progress on the job. Progress is calculated as a percentage of overall job volume. Introduced in Datameer 7.5. |
| das.job.production-mode | Set to |
Hadoop Properties
| Name | Default Value | Description |
|---|---|---|
| fs.AbstractFileSystem.hdfs.impl | org.apache.hadoop.fs.Hdfs | Property is required for successfully starting yarn application as these properties are stripped out while setting up the overlay by DAS framework. |
| io.compression.codecs.addition | datameer.dap.common.util.ZipCodec,datameer.dap.common.util.LzwCodec | Property is required for successfully starting yarn application as these properties are stripped out while setting up the overlay by DAS framework. Additional comma=separated compression codecs that are added to io.compression.codecs |
| das.yarn.available-node-vcores | auto | This property sets the number of available node vcores and is used in order to calculate the optimal number of splits and tasks (numberOfNodes * das.yarn.available-node-vcores). It can be set either to the number of free CPUs per node, or it can be set to auto. In auto mode, Datameer fetches information about the vCores from every node and sets das.yarn.available-node-vcores to the average of the available vCores. |
| das.job.health.check | true | Turn das job configuration health check on for cluster configuration. |
| das.local.exec.map.count | 5 | DAS property to influence the number of mappers in Local Execution mode. |
Other Properties
| Name | Default Value | Description |
|---|---|---|
YARN MR2 Framework Properties | ||
das.yarn.base-counter-wait-time | 40000 | YARN Counters take a while to show up at the Job History Server, so we use this base wait time + a small factor * the number of executed tasks to wait for the counters to finally show up. |
TEZ Execution Framework Properties | ||
das.tez.session-pool.max-cached-sessions | auto | Maximum number of idle session to be held in cache. 0 means no session pooling, auto uses the number of nodes in the cluster as value for the maximum number of sessions. |
das.tez.session-pool.max-idle-time | 2m | The timeout for the sessions held in pool for which they wait for DAG to be submitted. |
das.tez.session-pool.max-time-to-live | 2h | Maximum amount of time a tez session will be alive irrespective of being idle or active since its start time. |
tez.runtime.compress | true | Settings for intermediate compression with Tez. |
tez.runtime.compress.codec | org.apache.hadoop.io.compress.SnappyCodec | Settings for intermediate compression with Tez. |
framework.local.das.parquet-storage.max-parquet-block-size | 67108864 | For local execution framework setting the max parquet block size to 64MB(can't be raised beyond 64MB but, can be lowered) by default. |
tez.shuffle-vertex-manager.desired-task-input-size | 52428800 | Set the input size for each TEZ sub-task. |
Hive Properties | ||
| dap.hive.use-datameer-file-splitter | fales | Property decides whether Datameer should use Datameer's FileSplitter logic to generate RewindableFileSplits or Hive's own splitting logic. |
Windows Properties | ||
| windows.das.join.disabled-strategies | MEMORY_BACKED_MAP_SIDE | By default, memory backed joins are enabled on Windows platform, if required to disable, please uncomment the property. |
| mapreduce.input.linerecordreader.line.maxlength | 2097152 | Controls the maximum line size (in characters) allowed before filtering it on read. Below value is around a maximum of 4MB per line. |
Error Handling PropertiesAs of Datameer 7.5 | ||
workbook.error-handling.default | IGNORE | Legal values for workbook error handling are IGNORE, DROP_RECORD, ABORT_JOB. The equivalent error handling modes in the UI are Ignore, Skip and Abort. |
export-job.error-handling.default | DROP_RECORD | Legal values for export job error handling are IGNORE, DROP_RECORD, ABORT_JOB. The equivalent error handling modes in the UI are Ignore error, Drop record and Abort job. |
import-job.error-handling.default | DROP_RECORD | Legal values for import job error handling are DROP_RECORD, ABORT_JOB. The equivalent error handling modes in the UI are Drop record and Abort job. |
| data-link.error-handling.default | DROP_RECORD | Legal values for data link error handling are DROP_RECORD, ABORT_JOB. The equivalent error handling modes in the UI are Drop record and Abort job. |
Adding Custom Properties
Adding custom properties applied to all jobs
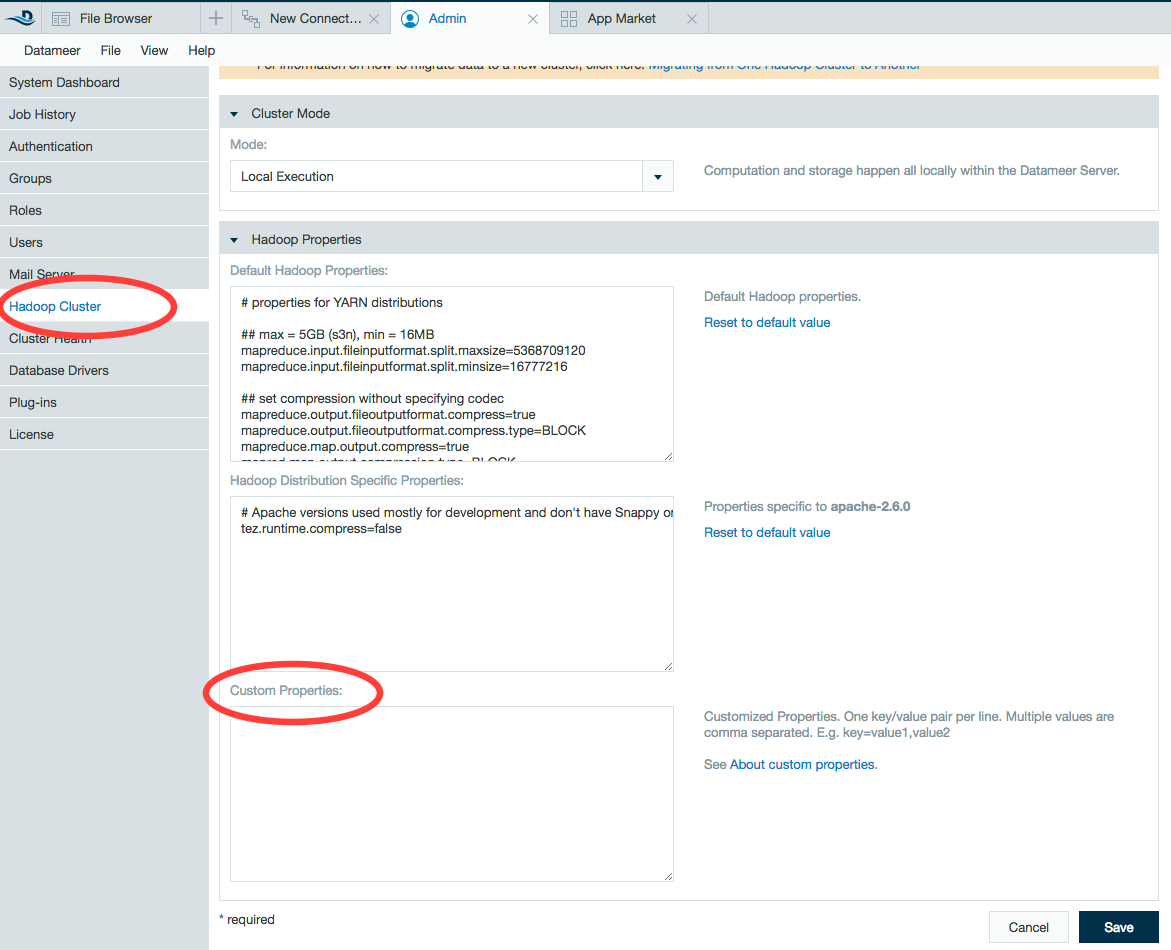
Custom properties can be added in the Admin tab under Hadoop Cluster. Custom properties added under the Hadoop cluster settings are applied system-wide.
- Click Edit.
- Enter the Hadoop property.
- Adjust the value.
- Click Save.
Adding custom properties applied to specific jobs
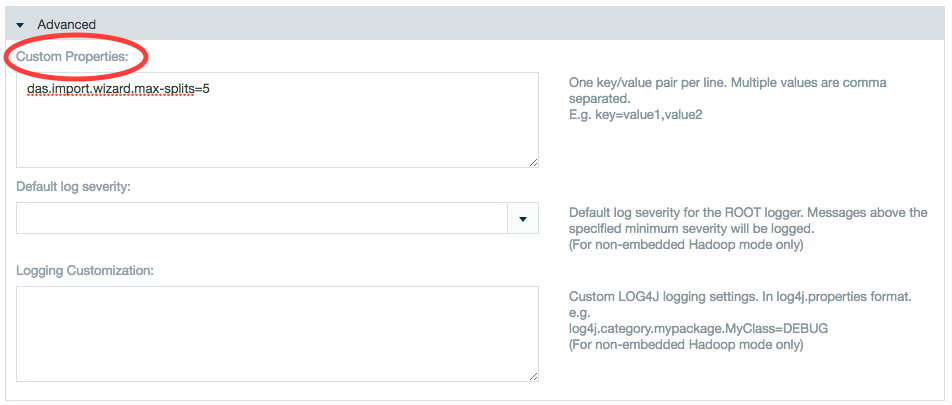
Custom properties can also be added to a workbook configuration. Custom properties added under the individual workbook settings will be applied only to that workbook.
- Save a new workbook or configure an existing workbook.
- In the Advanced section, enter the Hadoop property
- Adjust the value.
- Click Save.
Editing Custom Properties for Compressed Data
When importing compressed data, the requirements are different for settings custom properties than other custom properties.
To decompress data you're importing, all compression codec details need to be put within the conf/das-common.properties files.
This includes, for LZO compression:
io.compression.codecsio.compression.codec.lzo.classmapred.map.output.compression.codec
As a best practice, put all compression details in the properties files, and adjust their tuning parameters, if necessary, in the interface.