7.1 New and Noteworthy
- Charles Bishop (Deactivated)
- Andreas Küster (Unlicensed)
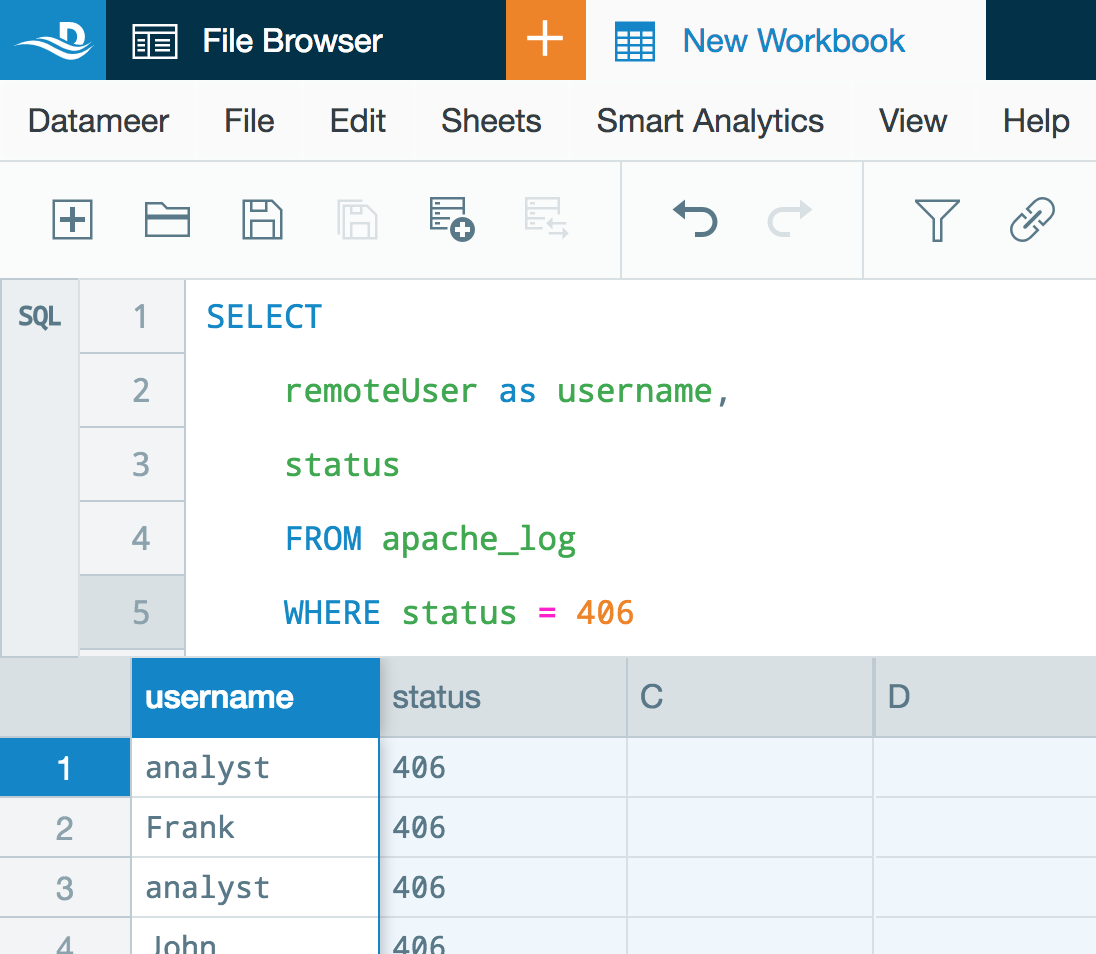
SQL Editor Worksheet (Beta)
SQL worksheets are available as of Datameer 7.1 as a beta feature.
An SQL editor interface has been added to Datameer. Creating an SQL worksheet gives you the ability to write SQL queries directly in a workbook. Users working within SQL worksheets can utilize this feature to combine processes that might take several steps using the traditional interface.
Updated Amazon S3 Connector
The new Amazon S3 Native connector has been added and gives a boost to performance compared to the original S3 connector. The performance improvement comes from multipart technology in the uploading parameters.
This connector also has the ability to export to S3 buckets even without access to read the getObjectMetadata()method.
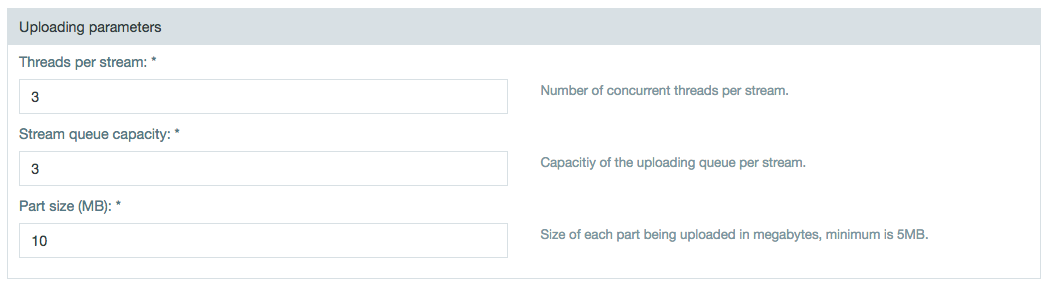
Currently, the S3 Native connector is available for export jobs with the import feature scheduled for a Datameer update in the near future.
Exporting data
Comprehensive improvements for exporting into HiveServer2
New improvements exporting into existing partitioned Hive tables.
Output format
Whereas it was only possible to write in Hive tables formatted as a textfile, Datameer now has the ability to export to tables which are formatted as a sequencefile, rcfile, avro, orc, or parquet. This allows you to benefit from the advantages of these fast formats.
Hive data type support
In Datameer v6.4 we extended the list of supported Hive data types for export with decimal, date, and timestamp. Now we extend this list again with tinyint, smallint, int, float, and varchar. This allows you to optimize Hive tables to the data types you really need while ensuring full compatibility to Datameer's Hive export.
| Datameer Value Type | void | boolean | tinyint | smallint | int | bigint | float | double | decimal | string | varchar | char | timestamp | date | binary | array <data_type> |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| STRING | ||||||||||||||||
| BOOLEAN | ||||||||||||||||
FLOAT | ||||||||||||||||
| INTEGER | ||||||||||||||||
| DATE | ||||||||||||||||
| BIG_DECIMAL | ||||||||||||||||
| BIG_INTEGER | ||||||||||||||||
| LIST |
Partition support
Until now, the advantages of partitioning could only be used for importing data. Datameer v7.1 brings you the ability to export into existing Hive partitions for the first time. In addition, Datameer not only supports date partitions (as for importing data) but all available types such as string partitions.
Mapping validation
The order of the columns in a workbook and in a Hive table no longer need to be identical. Also, mapping errors are now clearly marked in a red color (in the UI) for quicker troubleshooting.
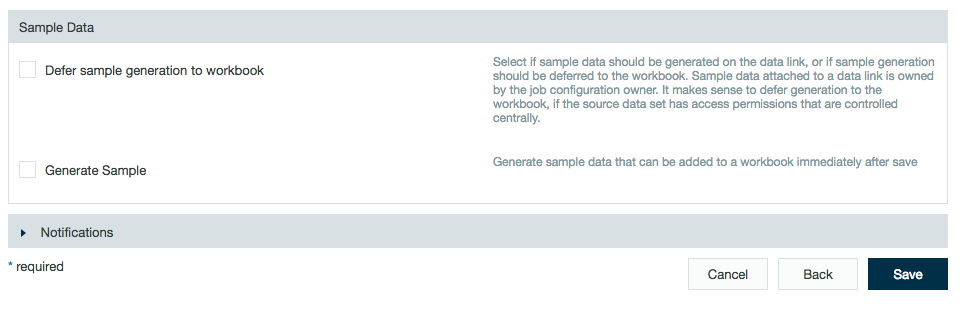
Defer Importing Sample Data from a Data Link
For data links, users have the option to generate sample data immediately after saving the data link (this saves the sample data to the DM private folder during the data link ingestion) or deferring sample data generation until using the data link in a workbook. Deferring sample generation is useful for when the data link is available to multiple users but each user may have different access to the original source of the data link. When deferring sample data, the sample data is created and stored in the DM private folder by the workbook user rather than the data link creator. This sample data access still follows impersonation security policies (e.g., Sentry/Ranger).
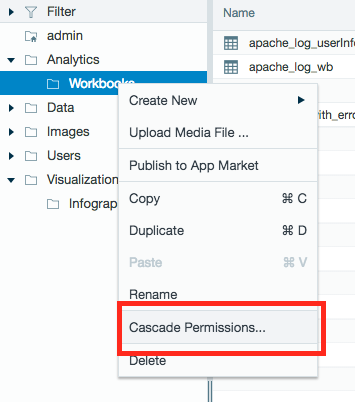
User Permissions
Cascading permissions
You can now speed up the task of setting permissions with the cascading permissions feature. The owner of a folder (or administrator user) can update the permission settings for all artifacts, files, and subfolders within the folder by cascading the permissions. The permissions are cascaded to all members of a Datameer group or the owner can cascade the permissions for all Datameer users.
Removal of support HSQL_HTTP
Datameer no longer supports the connection and import from an HSQL_Http database. HSQL_File continues to be supported.
Scheduling Jobs Made Easier
Import jobs, data links, and export jobs are able to run on a schedule you set. This schedule for each job is available in the inspector under the Information tab but was only available to edit within the job's wizard configuration, and to access this schedule you must navigate through the wizard to the scheduling section. As of Datameer 7.1, you can access and edit a job's scheduling configuration directly from the inspector in the file browser under the new Config tab.
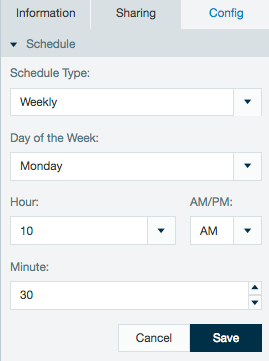
Schedules created with non complex cron patterns are converted automatically in the inspector. Select Schedule Type and Custom from the drop down menu to view or edit the schedule cron pattern.
Additions to Supported Hadoop Distributions
Older Hadoop distributions might no longer be supported as of Datameer v7.0. See Supported Hadoop Distributions for all supported distributions.
Support for Hive Server 1 and Hive Server 2 Using HDP 2.6
HDP 2.6 supports the use of Hive 1.2 and Hive 2.1.
Datameer's default HDP packaging supports Hive 2.1. In order to use Hive 1.2 with HDP 2.6, you need to download and install the HDP Datameer artifact with the suffix "-hive1".