JDBC (HiveServer)
Hardware Recommendation
To use the JDBC (HiveServer) connector, Datameer X recommends a Hadoop cluster with at least 16 vCPU and 30 GB RAM.
Property Recommendation
The following property changes might help to reduce problems from hardware limitations:
- das.job.map-task.memory=1024
- das.job.reduce-task.memory=1024
- das.job.application-manager.memory=1024
Performance Constraints
Native Hive connectors (Hive1 and HiveServer2) use a file based approach. Through these connectors, Datameer X connects to Hive at the very beginning and requests the table description to get the data source schema and its location in HDFS. Datameer X then accesses the data directly from HDFS. This method has an efficient parallel ingestion process and achieves a great performance level. However, this approach prevents the use of custom queries or ingesting data from Hive views.
Datameer's Hive JDBC connector allows users to benefit from custom queries and ingestion from views, but has performance constraints to be aware of.
What happens when you access Hive via JDBC (E.g., Beeline)? A user creates a query and submits it to the Hive service. The Hive service compiles a batch job (E.g., MapReduce, Tez, Spark) and submits it to a Hadoop cluster for processing. Performance of this job depends on the Hive configuration (execution frameworks, requested containers memory) and the cluster's capacity. As soon as this application is competed, the results are returned to the Beeline client or written to a file if requested. Results streaming from Hive to a client can also be started during application processing.
Datameer X compiles a batch job and submits it to the cluster when accessing Hive data via a JDBC connection. This job also makes a JDBC connection to Hive and requests Hive to execute the corresponding query (SELECT or a user's custom query). The Hive service compiles and submits its own Yarn application to process this request.
There are several bottlenecks in terms of performance in this process.
- The performance of the job submitted by Hive depends on available cluster resources, their allocation, and the ability to parallelise the calculation.
- The performance of the job initially submitted by Datameer. Because it is difficult and often inefficient to split the requests sent to Hive via JDBC, by default Datameer X uses a single container to run such executions. This means that all data returned by Hive are processes written to HDFS by a single thread.
When the performance level is critical for your use-case, Datameer X recommends using the HiveServer2 connector.
Configuring JDBC (HiveServer) as a Connection
In order to import from your database using Java Database Connectivity (JDBC), you must first create a connection.
- Click + (plus) button and select Connection or right-click in the browser and select Create new > Connection.
- From drop-down list, select HiveServer2 (JDBC) as the connection type. Click Next.
Enter the Hive host name, port and URL properties.
Enter any additional connection properties, if needed.
Currently, the connector is for import only.
Select an authentication method and add the required username and password.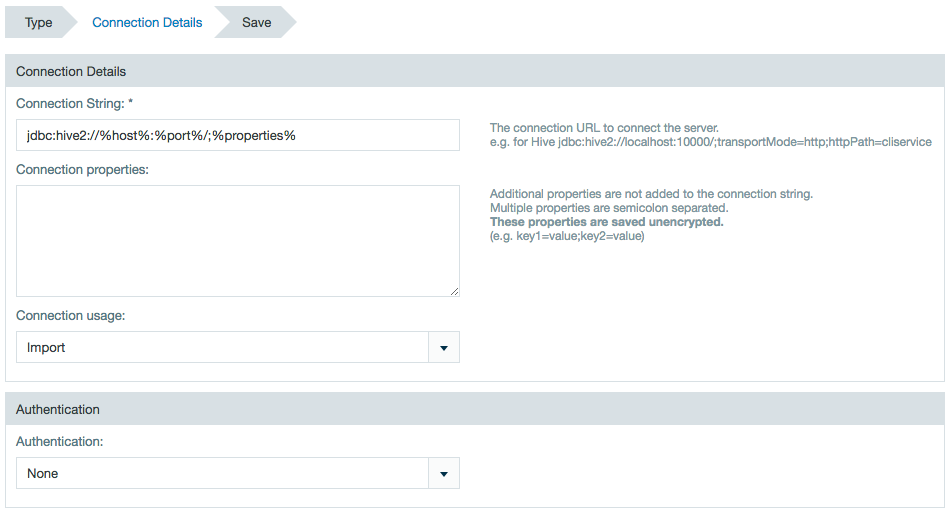
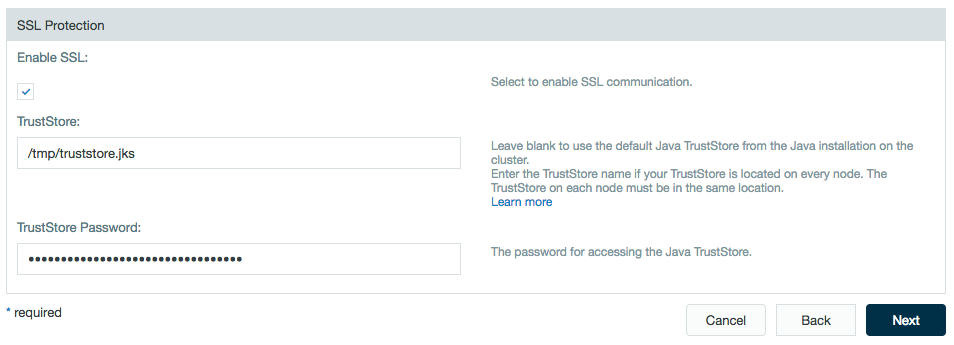
Select the checkbox to enable SSL and enter the TrustStore address and password.
Click Next.
Helpful keystore and truststore information
In order to use SSL you need two pieces, a keystore and a truststore.
Keystore
A keystore is located on the server side only. This file contains the private key to decrypt messages. A keystore isn't delivered by the JDK. You have to create your own keystore and import the key you got from your Certificate Authority (CA) or you can import a self generated key into your keystore.
Truststore
A truststore is located on the client side (e.g., Datameer). This file contains:
- The public part of the private key from the keystore backed in a certificate (in case of self signed certificates).
- All other root certificates called CA-certificates. These certificates are used to verify if the private key from the server is valid (SSL Handshake).
You can use the truststore provided by the JDK from Oracle. This file is located under
$JAVA_HOME/jre/lib/security/cacerts.Hive Server Side
You can turn on SSL if you want to protect the communication between Hive Sever and any other Hive Client. To do that edit your hive-site.xml and add the following lines. (The values are just examples)
<property> <name>hive.server2.use.SSL</name> <value>true</value> <description>enable/disable SSL </description> </property> <property> <name>hive.server2.keystore.path</name> <value>/home/datameer/hive/security/hive.jks</value> <description>path to keystore file</description> </property> <property> <name>hive.server2.keystore.password</name> <value>datameer</value> <description>keystore password</description> </property>
The property
hive.server2.keystore.pathis a java keystore (JKS) which contains the private key to decrypt messages.Hive Client Side
The client is using a truststore to hold certificates which are trustworthy. You can define an own truststore or you can use the default truststore provided by Oracle. This truststore is located under $JAVA_HOME/jre/lib/security/cacerts.
There are two types of a certificate you can import into a truststore, a self signed certificate or a CA signed certificate.
Self signed certificate:
These certificates aren't part of the default truststore provided by Oracle located under
$JAVA_HOME/jre/lib/security/cacerts. You must import the self signed certificate into your truststore if you want to use self signed certificates for SSL.CA signed certificate:
You can buy a certificate by a Certificate Authority (CA). Oracle trust many different CA's. You can look into this truststore via the command
keytool -list -keystore $JAVA_HOME/jre/lib/security/cacertsYou don't need to import your CA signed certificate into the JDK truststore, if your CA where you bought your cert is part of the truststore of the JDK.
- If required, add a description and click Save.
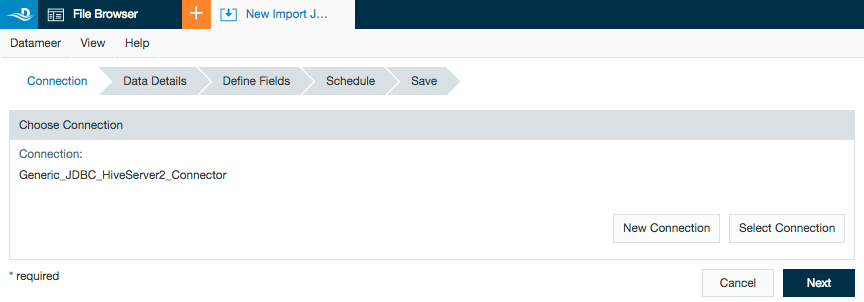
Importing Data from HiveServer2 with a JDBC Connector
After configuring a JDBC connection, using the wizard you can set up one or more import jobs (or data links) which access the connection.
- Click + and select Import Job or right-click in the browser and select Create new > Import Job .
- Click Select Connection and choose the name of your JDBC connection (here - Generic_JDBC_HiveServer2_Connector) then click Next.
Select to import from a Table, View, or by entering a SQL select statement.
A checkbox is available to select to enable/disable the collection of preview data displayed on the next page.
.png?version=1&modificationDate=1573573950000&cacheVersion=1&api=v2&width=700&height=458)
If you selected the box to preview data, a preview of the imported data is displayed.
From the Define Fields page you can change the data field types and if necessary, set up date parse patterns.
The preview includes the columns within the Hive partition but not the partition values. If needed, add the partition values to the import job by marking the included box under the column name.
By default, the column names are "<tablename>_<columnname>". This feature can be turned off inhive.site.xmlwith the following property:hive.resultset.use.unique.column.names=false.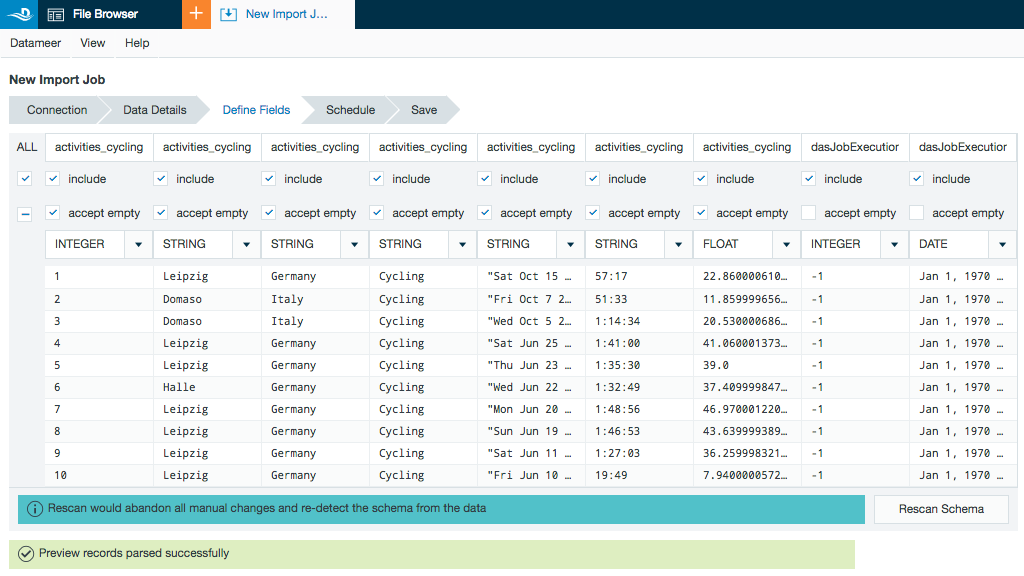
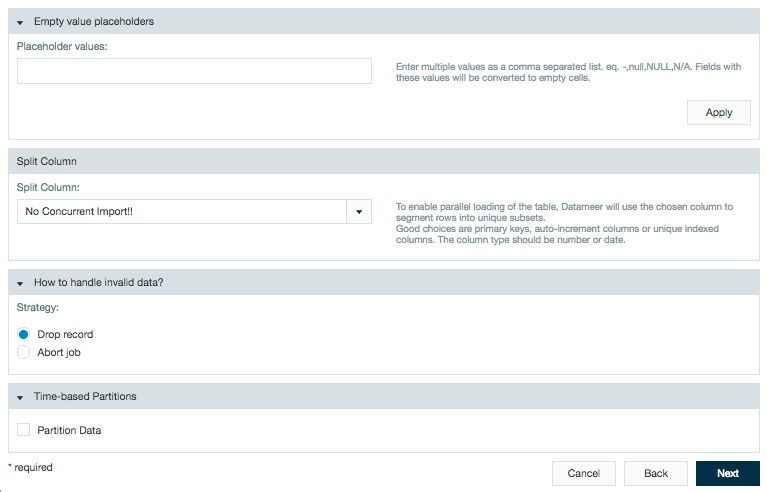
Additional advanced features are available to specify how to handle the data.
Empty value placeholders gives you the ability to define what text converts to empty cells.
Split columns enables parallel loading of a table. The selected column will have its rows segmented into unique subsets. If you don't want to split a column, selected "No Concurrent Import!!"Datameer X does not control splitting from data ingested from the Hive JDBC connector. The splitting is controlled via the Hive JDBC.
When splitting columns it is possible to create a deadlock situation on your Hadoop cluster. This can be prevented by properly configuring the Limit # of Mappers to 1 on the Scheduling page under the section Advanced .
Datameer X has a default split count of 1. It is recommend to not increase the splitting as it could have a negative performance impact.
Time-based partitions let you partition data by date. This features allows calculations to run on all or only specific parts of the imported data. See Partitioning Data in Datameer for more information.
Datameer X jobs are compiled outside of Hive and don't have the same restrictions as Hive queries.
A filter is similar to a where clause. It restricts the results on only include results that match the requested search criteria.
Review the schedule, data retention, and advanced properties for the job.
Add a description, click Save, and name the file.