System Dashboard
- Juliane Wetzel
Viewing the System Dashboard
To view the system dashboard, click the Admin tab on the top of the page. The System Dashboard tab is selected by default.
The list of current running jobs is displayed here. You can view job details and run specific jobs.
Job scheduler
The Job Scheduler allows you to pause incoming jobs being submitted to the cluster.
To pause incoming jobs to the cluster:
- Click Pause.
- To restart jobs being allowed to the cluster click Resume.

Auto compaction ensures that appended import jobs always store data efficiently even if they run very frequently. Example: If an import job is run every hour, this generates 24 files every day. If you run it even more often there are more files of smaller size. This process could lead to a high fragmentation of your data into a lot of small files and Hadoop is less efficient when processing these. Auto compaction compacts those files automatically on a daily or monthly basis depending on the configured schedule of an import job. This process ensures the best system performance regardless of the import job update interval. Click Pause to stop auto compaction. To restart it, click Resume.
If you have time-based partitioned imports in append-mode on an hourly or daily basis without auto compaction running, the application database might slow over time.
Auto compaction runs as low priority and only compacts data of a completed day or month (partition) and never on the current day of data or the configured date. Compaction only runs daily or monthly - you can't configure it for a different time period. Prior to and during compaction for a particular import job, the workbook continues to use the existing data. Once compaction is complete, the next workbook execution uses the compacted data. It isn't possible to trigger the compaction job manually.

If Datameer X has been shut down with jobs still in the queue, upon restart, those jobs resume running as scheduled. To pause any scheduled jobs upon starting/restarting Datameer X use the conductor.sh option --jobschedulerPaused.
Running Jobs
To view current running or queued jobs, click the Admin tab on the top of the page, the System Dashboard is selected by default. In the Running Jobs section, you can view the list of jobs that are in the process of running or are in a queue to be run.
From here you can view job details including the job ID, job name, user the job was triggered by, when the job started, expected or estimated time of completion, a progress bar, and an option to abort/cancel a job.
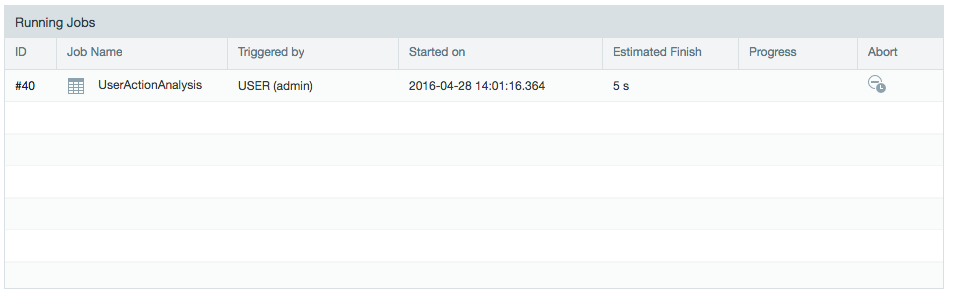
- The default number of jobs that can run at once on Local Execution is 5.
- The default number of jobs that can run at once on a Hadoop cluster is 25.
The jobs shown to be running or queued are for processes within Datameer. There is a second queue jobs must go through on the Hadoop cluster. Datameer X submits jobs to Hadoop for processing. The Hadoop administrator may observe the job's status by monitoring the job Tracker or YARN Resource Manager for the Hadoop cluster.
View job details
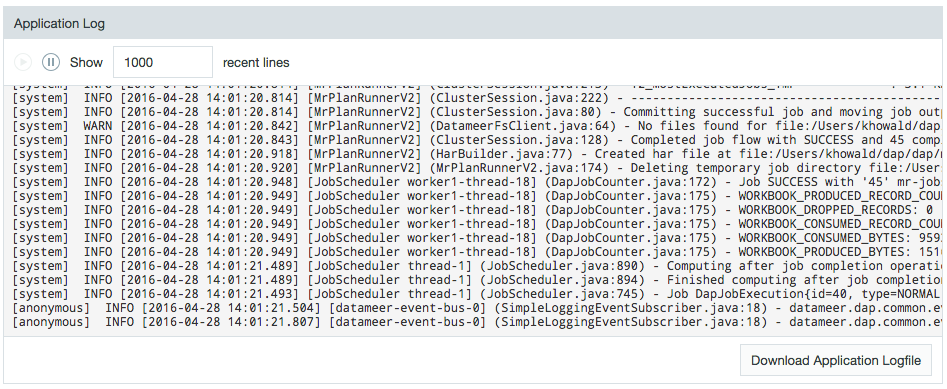
You can view the job history, view the log file, or download the log file. You can also run a job or view the source details.
To view job history, view the log file, or download the log file:
- Click the Admin tab on the top of the page, then click the Jobs tab on the left.
- Select the option next to name of the job and click the Details button.
- The Counter History shows how many records are processed and how many are dropped.
- You can specify how many lines of the job logfile display. Use the scroll bar to view the log. (See Logfile details.)
- You can also click the Download Logfile link to download the log file.
- Use the play or pause controls to run or pause the job.
Log file details
To run a job:
- Click the Admin tab on the top of the page, then click the Jobs History tab on the left.
- Click the name of the job and click Run.
The job is queued, runs, and then displays the results.
Depending on the volume of data, a job might take some time to run.
To view source details:
- Click the Admin tab on the top of the page, then click the Jobs History tab on the left.
- Click the name of the job and click Workbook Details.
- From here, you can edit the workbook, by clicking Open. See 1Working with Workbooks to learn more.
- To view the complete data set, click View Latest Results. You can click the tabs to view each sheet in the workbook. You can scroll through the data, or click Go To Line to view a specific record. From here, you can click Open to edit the workbook.
From the Workbook Details page, click Details to view details about the job.
Smart Execution jobs, marked as YARN Applications in the manager, are listed as successful even if a problem leads to the Datameer X job failing.
Version information
- Shows the version number.
- Shows the version revision.
- Shows the Hadoop distribution version.
- Shows the product ID.
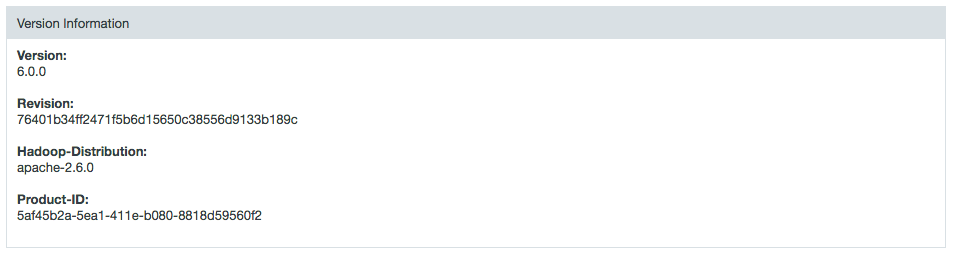
Product ID
A product ID is generated in the Java preferences store when an instance of Datameer X is installed. This Product-ID is then tied to the license.
The initial product ID is needed in order for Datameer X to function with the license. If a new product ID is generated, the license is no longer valid.
Possible reasons that a new product ID would generate:
- Java preference store is deleted.
- Datameer X is copied and set-up on a new machine. This is because the Java preference store on the new machine doesn't have a product ID, so a new one is created.
- If a different user starts/restarts Datameer.