Set Up Datameer on YARN
Setting Up Datameer X with YARN
Datameer X can connect to YARN cluster, depending on the Hadoop distribution used.
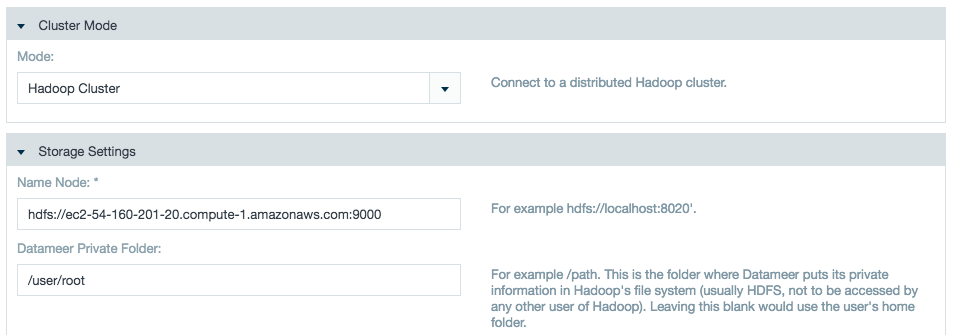
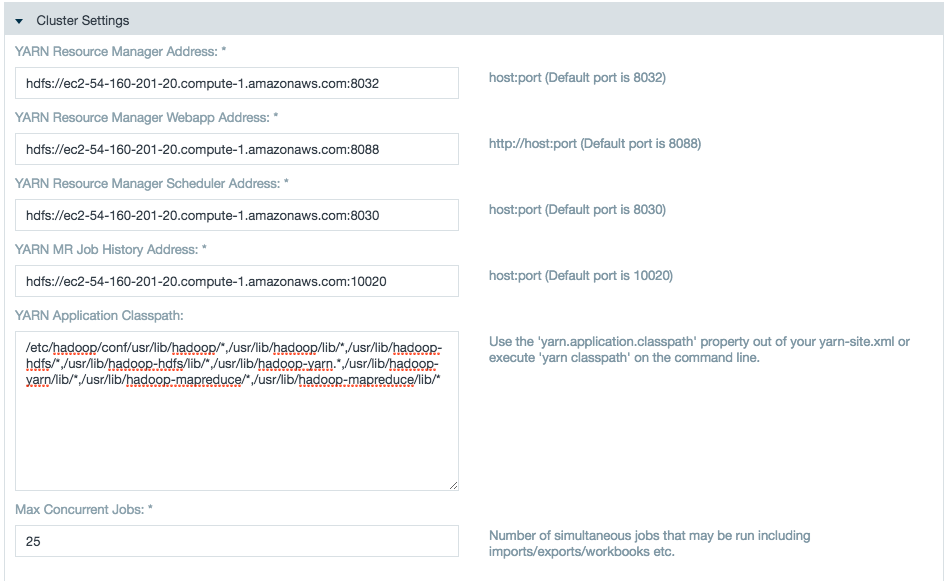
An admin has complete configuration in the Hadoop Cluster configuration page. The Hadoop Cluster configuration page requests for different configurations for YARN cluster when compared with a classic MapReduce cluster.
Following are the new configurations required to be setup by a Datameer X admin in Hadoop Cluster configuration page (the user interface suggests the default values to be used):
| Configuration | Type |
|---|---|
| Resource Tracker Address | host:port |
| Yarn Resource Manager Address | host:port |
| Resource Manager Webapp Address | host:port |
| Yarn Resource Manager Scheduler Address | host:port |
| Yarn MR Job History Address | host:port |
| Yarn Application Classpath | string: class path |
While working with secure Kerberos mode the Hadoop Cluster configuration page asks for the YARN Principal as well.
Debugging options
Some options for better debugging:
By default the container logs are deleted once the container is released, so you never see the actual reason for the failing container. The log message provided in the node managers log is not sufficient.
For better and faster debugging set the below configuration in yarn-site.xml (on all nodes):
<property> <name>yarn.nodemanager.delete.debug-delay-sec</name> <value>-1</value> </property>
values here can be any positive integer, -1 implies never delete
Restart node manager to reflect the changes. After this change you should see container logs in the yarn log folder.
Occasionally you can even look at launch_container.sh script to check the runtime configurations of the application container.
Common YARN Configurations
#Configs set by in one of your SX Lab Environments das.execution-framework.small-job.max-records=1000000 das.execution-framework.small-job.max-uncompressed=1000000000 tez.am.container.reuse.enabled=true tez.am.launch.env=LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_COMMON_HOME/lib/native/ tez.task.launch.env=LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_COMMON_HOME/lib/native/ #das.tez.reduce-tasks-per-node=6 #tez.shuffle-vertex-manager.desired-task-input-size=50485760 das.tez.session-pool.max-cached-sessions=3 das.tez.session-pool.max-idle-time=600s tez.am.session.min.held-containers=1 tez.am.container.idle.release-timeout-min.millis=60000 tez.am.container.idle.release-timeout-max.millis=60000 das.execution-framework=Smart das.map-tasks-per-node=16 ### We've seen this in virtual environments mapreduce.map.memory.mb=1536 mapreduce.map.java.opts=-Xmx3226m mapreduce.reduce.memory.mb=2240 mapreduce.reduce.java.opts=-Xmx4704m yarn.app.mapreduce.am.command-opts=-Xmx2016m yarn.scheduler.minimum-allocation-vcores=1 yarn.scheduler.maximum-allocation-vcores=8 yarn.nodemanager.resource.memory-mb=13440 yarn.scheduler.minimum-allocation-mb=1024 yarn.app.mapreduce.am.resource.cpu-vcores=1 mapreduce.reduce.cpu.vcores=1 yarn.nodemanager.resource.cpu-vcores=8 yarn.app.mapreduce.am.resource.mb=2240 yarn.scheduler.maximum-allocation-mb=13440 mapreduce.map.cpu.vcores=1 mapreduce.task.io.sort.mb=896 #Smaller jobs got better performance with customer FLS Connect with this setting: tez.shuffle-vertex-manager.desired-task-input-size=52428800
Configuring Datameer X When Upgrading from MR1 to MR2
Complete the following steps to configure Datameer X when upgrading from MR1 to MR2:
- Stop Datameer.
- Take a dap database backup.
Execute the following query on the dap database:
UPDATE property SET value = "LOCAL" WHERE name = "hadoop.mode";
- Start Datameer.
- Login and configure the MapR 4 MR2 settings on the Admin > Hadoop Cluster tab.
Configuring YARN with High Availability
To configure YARN with High Availability, see Configuring Datameer.