Importing Data
- Juliane Wetzel
When you import data, you import it into a connection, which is a collection of data from various types of files and databases, and then create a workbook that uses data from multiple sources (for example, a user list from a database and an Apache error log file). See Types of Data Supported for information about the types of databases and files that you can import into Datameer.
Once the connection is set up, you create import jobs to import the data you want to use. You can also edit, rename, create a copy, run, view the full data, view the details and information, or delete an existing import job.
See Define File Path Range to learn how to use a date range to limit which files get imported.
Obfuscation is available with Datameer's Advanced Governance module.
Creating an Import Job
To create an import job:
- Click the + (plus) button and select Import Job or right-click in the browser and select Create new > Import job.
- Click Select Connections, choose the connection and click Select, then select the file type and click Next. Click New Connection to add a new connection if needed.
- Specify the file and folder location and click Next. You can use wildcard characters.
- The fields on the Data Details page depend on the type of the file, however, there are several fields in common. In the Encryption section, enter all columns to obfuscated with a space between the names. Note that when a column is obfuscated, that data is never pulled into Datameer.
See the following sections for additional details about importing each of the file types:- Apache log: specify the file or folder and the log format. See the samples provided in the dialog box for details.
- CSV/TSV files:
- Specify the delimiter such as"\t" for tab, comma ",", or semicolon ";".
- Specify if column headers should be made from the first non-ignored row.
- Specify the escape character to "escape" processing that character and just show it in Advanced Settings.
- Specify the quote character in advanced settings. If Enable strict quoting is selected, characters outside the quotes are ignored.
- Fixed width: specify the file or folder and specify if any of the first lines in the data should be skipped and then if column headers should be made from the first non ignored row.
- JSON: specify the file or folder and other parameters about what to parse within the JSON structure.
- Mbox: specify the file or folder. This is a format used for collections of electronic mail messages.
- Parquet: columnar storage format available in Hadoop.
- Regex Parsable Text files: specify the file or folder, a Regex pattern for processing the data (see note below), and specify if any of the first lines in the data should be skipped and then if column headers should be made from the first non ignored row.
- Twitter data: specify the file or folder.
XML data: specify the file or folder, the root element, container element, and XPath expressions for the fields you would
Custom Headers
For all types, you can:
- Specify that the column headers are in a separate file by selecting Provide custom schema. Indicate where the schema is located and the delimiter characters. The first row of that file is assumed to be column headers.
- Specify a number of lines to be ignored on import from the source data, including the header file using Ignore first n lines, under Advanced.
- View a sample of the data set to confirm this is the data source you want to use. Use the checkboxes to select which fields to import into Datameer. The accept empty checkbox allows you to specify if NULL and empty values are used or dropped upon import. Verify or select a data type for each column from the drop down menu. You can specify the format for date type fields. Click the question mark icon in the data format field to see a complete list of supported date pattern formats.
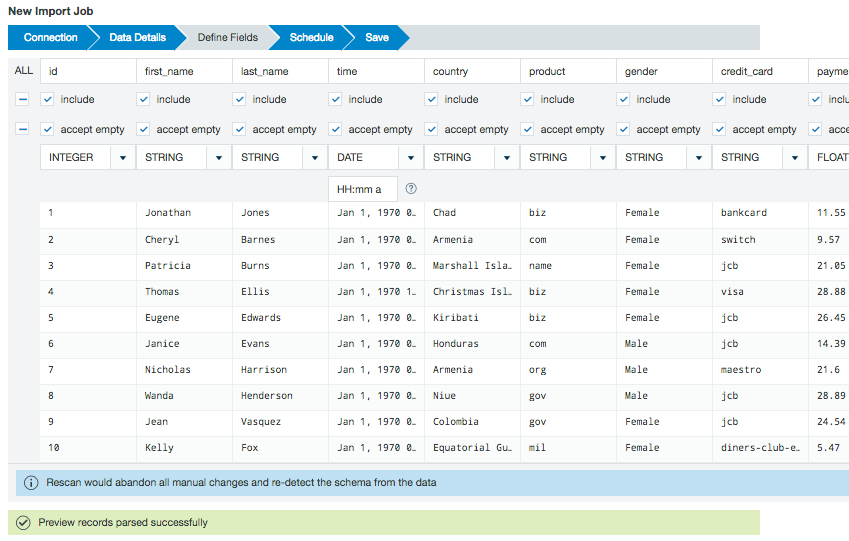
The Raw Records section shows how your data is viewed by Datameer X before the import.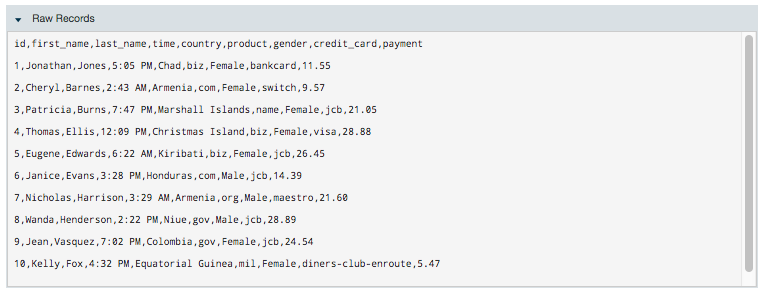
The Empty value placeholders section is a feature giving you the ability to assign specific values as NULL. Values added here aren't imported into Datameer.
The How to handle invalid data? section lets you decide how to proceed if part of a record doesn't fit with the defined schema during import.
Selecting the option to drop the record removes the entire record from the import job. The option to abort the job stops the import job when an invalid record is detected.
You can partition your data using date parameters. When this data is loaded into a workbook, you can choose to run your calculations on all or on just a part of your data. Also if you decide to export data, you can choose to export all or just a part of your data.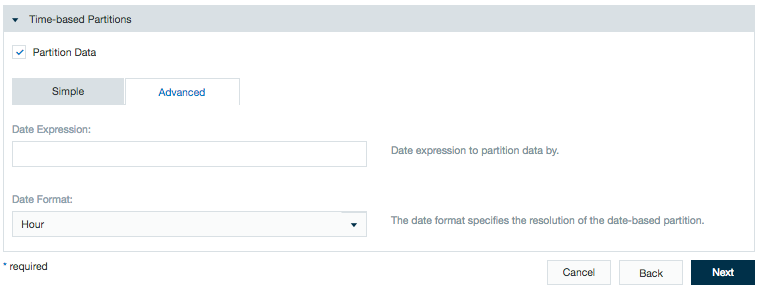
Click Next. Define the schedule details.
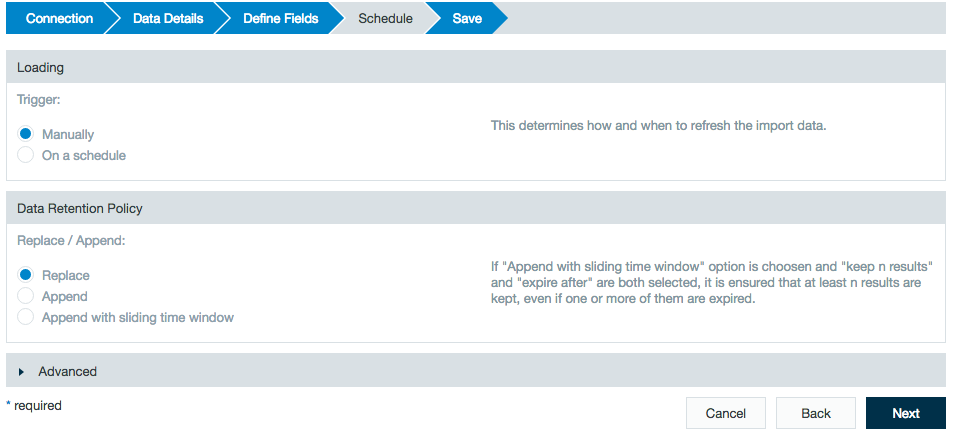
In the Loading section, select Manually to rerun the import job in order to update or On a schedule to run the import job update at a specified time.
In the Data Retention Policy section choose whether to replace new updated data or to append it to existing data when updating an import job. You also have the option to choose Append with sliding time window to define a range during which the update expires and how many results to keep.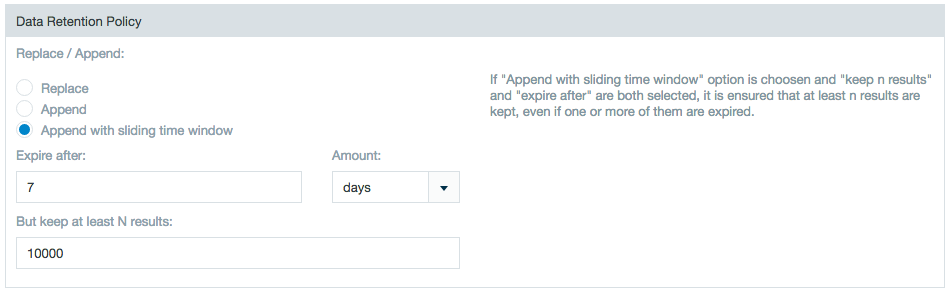
Adding or deleting columns from an appended import job
The appended import jobs can contain additional or fewer columns than the previously run import job. When the schema is rescanned, Datameer X notices that columns have changed so no data is lost.
However, data can be lost due to append changes in these circumstances:
- If a column name has been renamed then the schema uses the column with the new name and deletes data from the old column name.
- If the data type of a column has been changed
- If a change in the partition schema is made the data resets starting from the new change
Add a description, name the file, click the checkbox to start the import immediately if desired, and click Save. You can also specify notification emails to be sent for any error messages and when a job has completed successfully. Use a comma to separate multiple email addresses. The maximum character count in these fields is 255.
Note: Sample Regex pattern for importing data: (\S+) (\S+) (\S+) (\S+) (\S+) See Importing with Regular Expressions to learn more.
Type Conversions
- Integer columns can be imported as date by interpreting the integer value as UNIX timestamp or epoch timestamp.
- Date columns can be converted as integer, the converted columns are shown as an epoch timestamp.
- Strings can be converted to Boolean, where "false", "no", "f", "n" and "0" are converted to false and "true", "yes", "t", "y" and "1" are converted to true.
Raw Records
Click Raw Records to view an expanded sample of the raw data not in tabular format. Click Raw Records again to hide the raw data.
How to View and Edit the Job Settings
Some of these settings can also be accessed through the Save Workbook settings. The Save Workbook settings let you specify when jobs are run, how error handling should be done and specify who gets notified, and lets you specify what data is saved with the workbook and how much historical data (if any) is saved. See Configuring Workbook Settings to learn details about each of the settings.
To view and edit the job settings through the Import Data view:
- Click the File Browser tab.
- Click on Import Jobs in the navigation window on the left side of the screen.
- Highlight the name of the data source you want to view.
- Click Configure. (As of v6.3, click Open.)
- Click Next to view each type of job setting. You can also make changes.
- The Schedule screen has settings that can also be set through Save Workbook settings.
- Specify whether to replace or append data and whether to append using a sliding time window. You can then specify when the data should expire and how many results you should keep.
- Select which groups have view, edit, and run access permissions and specify what access permissions all users have.
- Click Save to save your changes. You can also click Rename to rename the import.
To view and edit the job settings through the workbook view:
- Click the File Browser tab at the top of the page.
- Click the name of the workbook you want to view.
- Click Configure. (As of v6.3, click Open.)
Viewing Dropped Records
If the import job runs with dropped records, the icon on the page listing all import jobs displays an icon "Completed with warnings" You can easily find out what caused the problem.
To view dropped records:
- Double-click the import job name.
- Click the recent listing ID in the History list.
- On the Import job run details page, view the Errors list to find out what happened.
The job details page showing Job History.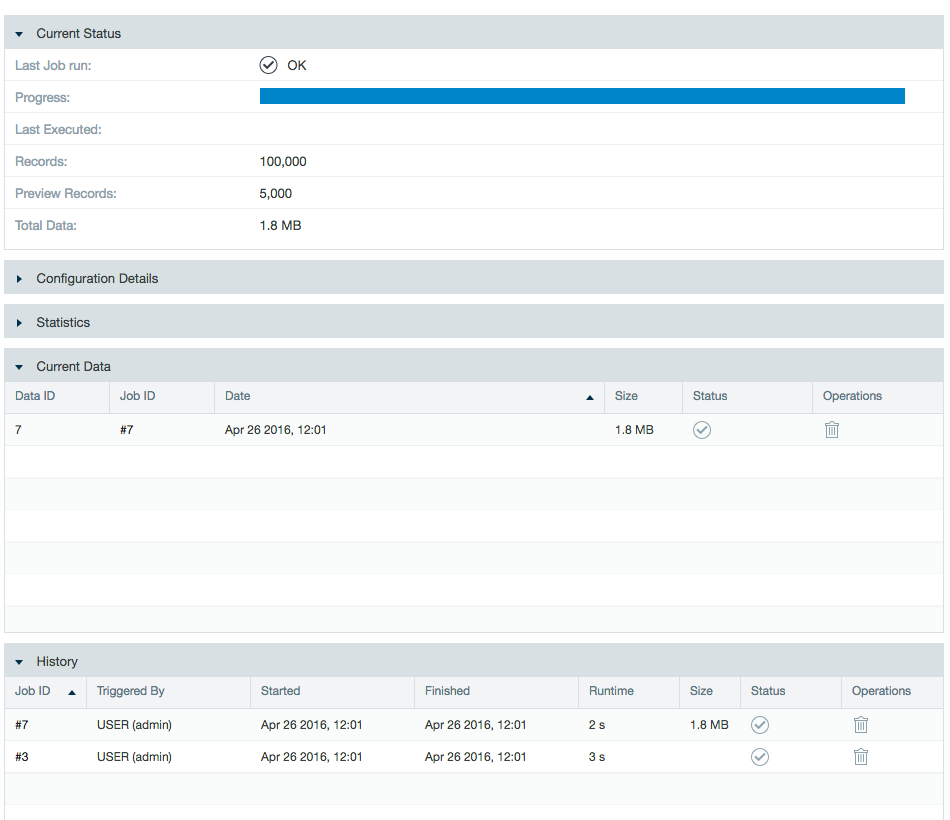
The details page showing the list of errors.
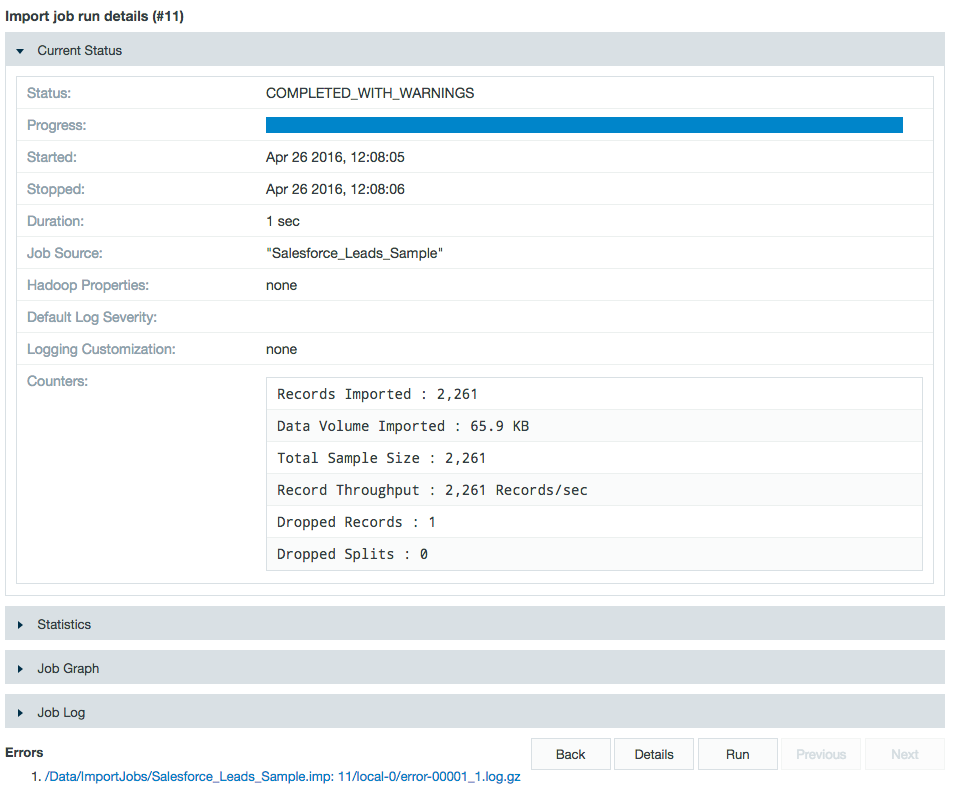
The error log shown when you click an entry in the list of errors.

The job run details page showing statistics and the job log file.
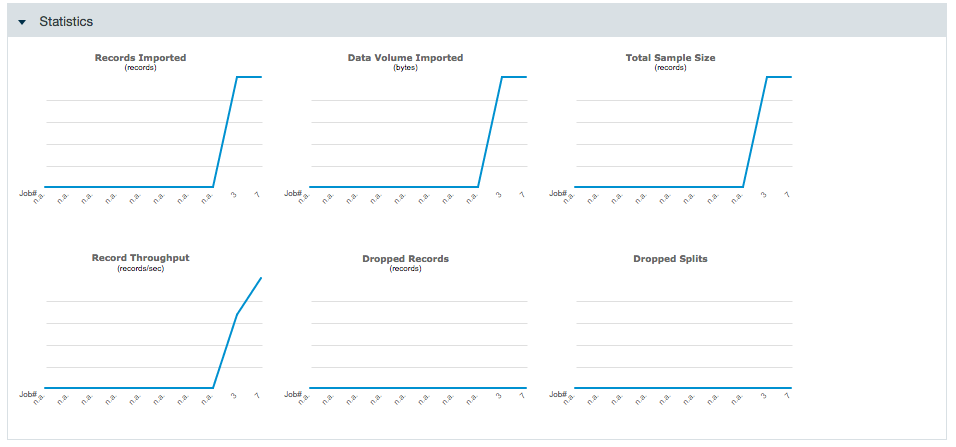
Use the links in the Job log file section to download the log file, download the job trace, or to report an issue to Datameer. When you click Report an issue, fill out the bug report and provide steps to recreate the error.
Scheduling Job Runtime
You have a great deal of flexibility in choosing when jobs are run. You can choose to run them manually or at a interval you specify.
- Create a new import job or right-click and select Open to open the import job configuration wizard.
- Under the Calculation settings, select Manually or Scheduled.
- When Scheduled is selected, specify a time for the import job to run.
- Click Save to save your changes.
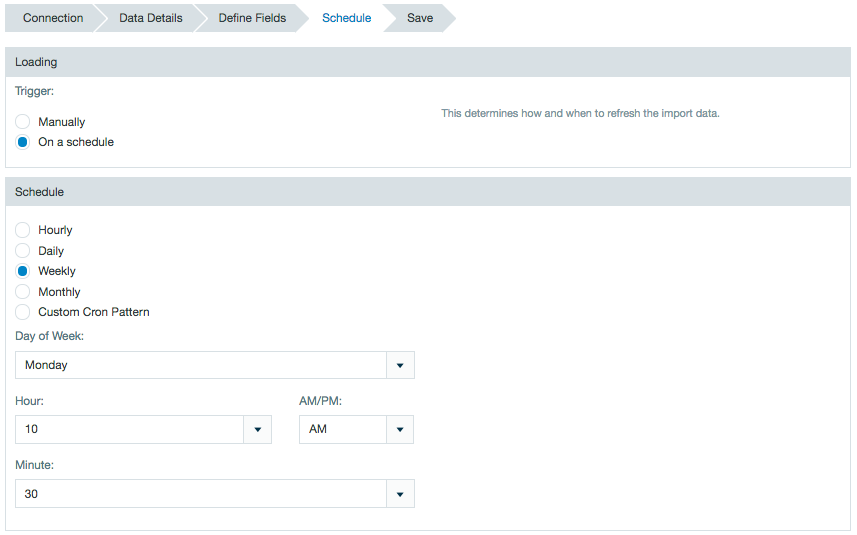
The schedule of an import job can also be viewed or edited from the inspector in the file browser.
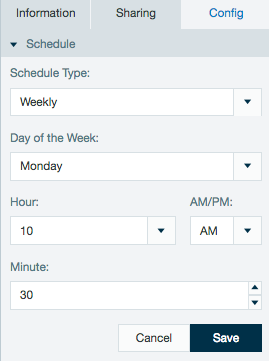
Schedules created with non complex cron patterns are converted automatically in the inspector. Select Schedule Type and Custom from the drop down menu to view or edit the schedule cron pattern.
Edit an Import Job
To edit an import job:
- Click the File Browser tab.
- Click Import Jobs from the navigation bar on the left side of the screen.
- Right-click the import job you want to edit and click Configure. (As of v6.3, click Open.)
- Make your changes and click Next to move through the screens.
- Click Save when you are finished. Note that after a schema change, saving the import job deletes data from previous job runs and aborts the job currently running. To keep previous data, use Save Copy As.
If just the partitioning has changed, the Save & Migrate button simply performs a migration rather than refetching data from the source.
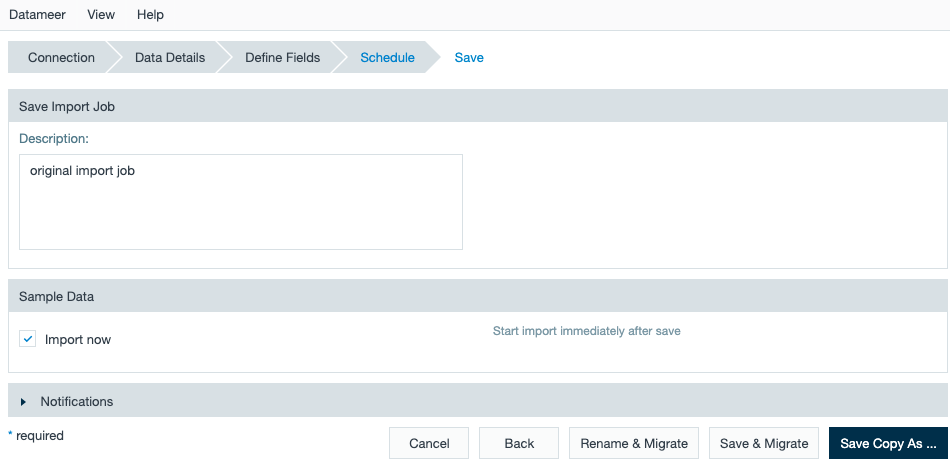
Create a Copy of an Import Job
You can create a copy of an import job. Here are some items to note if you copy an import job:
- Already imported data isn't copied.
- The metadata and job definition are copied, including the information and settings on the Schedule screen.
- To avoid unnecessary data volume consumption, Datameer X recommends reviewing the configuration after copying an import job.
To create a copy of an existing import job:
- Click the File Browser tab.
- Click Import Jobs from the navigation bar on the left side of the screen.
- Right-click the import job you want to copy.
- Click Duplicate.
The copy is created and named "copy of" plus the name of the original import job.
Run an Import Job
You can run an import job manually, or schedule it to be automatically run.
To run an import job manually:
- Click the File Browser tab.
- Click Import Jobs from the navigation bar on the left side of the screen.
- Right-click the import job you want to run and click Run.
Depending on the amount of data, this might take some time.
Delete an Import Job
Note that this deletes the import job, not the original data. It also deletes the imported data within HDFS to be removed by the Housekeeping service. Deleting an import job can't be undone. It a workbook is referencing the imported data, the workbook might not work.
To delete an import job:
- Click the File Browser tab.
- Click Import Jobs from the navigation bar on the left side of the screen.
- Right-click the import job you want to delete and click Delete.
- Click OK, then confirm the deletion.
Linking Data to a New Workbook
You can link data to a new workbook.
To link data to a new workbook:
- Click the File Browser tab.
- Click Import Jobs from the navigation bar on the left side of the screen.
- Double-click the import job name to link into a new workbook.
- Click Link Data in New Workbook.
- The data is loaded into a new workbook.
Viewing Import Job Upload Size and Monthly Upload Sizes
You can view the count of processed bytes for each upload and their total volume counting towards the license term.
To view the processed bytes per single job execution and totals for that job configuration of the import jobs:
- Click the File Browser tab.
- Click Import Jobs from the navigation bar on the left side of the screen.
- The size of last job run is displayed first and the total for that job configuration is displayed to the right in parentheses.
If a new license term starts and the import job is processed again, the count starts with a new total processed data amount.
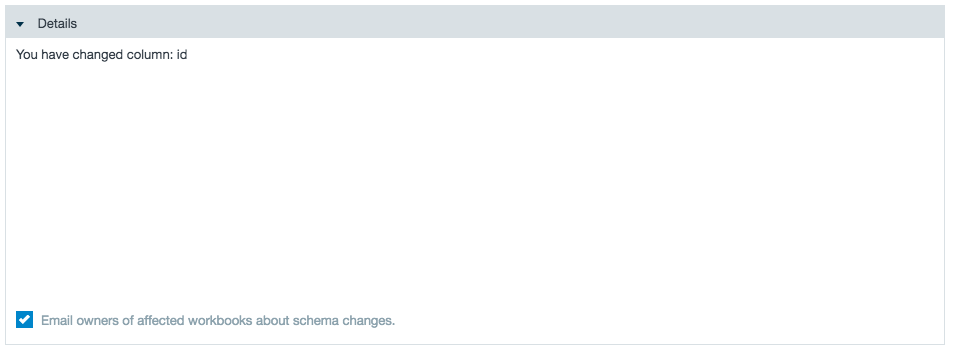
Identify Workbooks Affected by an Import Job Schema Change
Datameer X gives you a notice when editing an import job if a schema change affects a corresponding workbook.
To view which workbooks are affected by a schema change from the import data:
- Complete the import job configuration until reaching the Save section.
- Review the note box detailing the changes this configuration save has on the previous save and which workbooks are affected.
- Check the box to email users of the workbooks that are affected by the new schema changes.
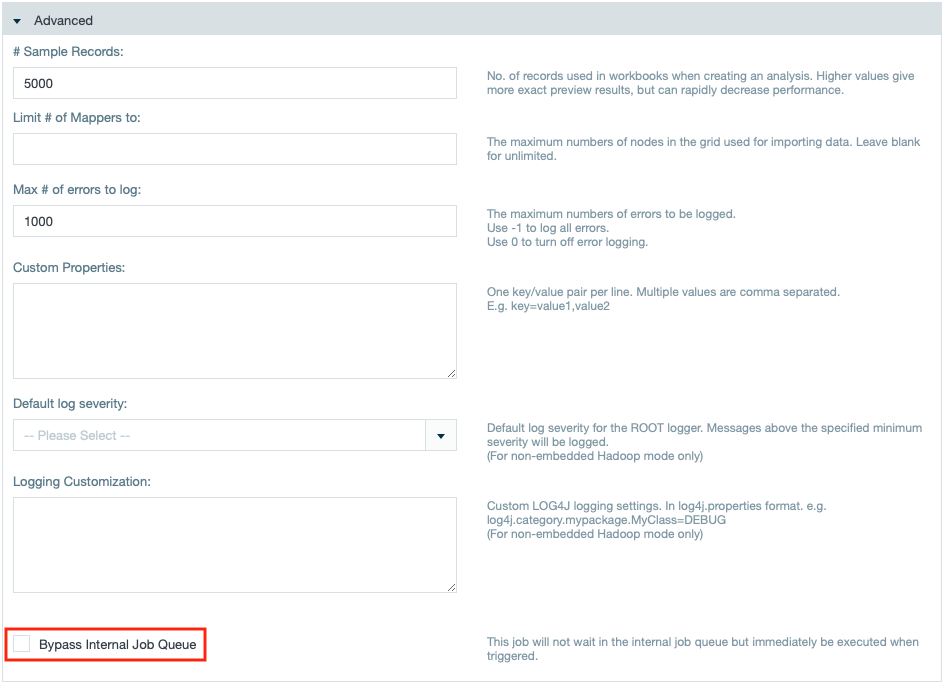
Priorizing an Import Job in the Job Scheduler
INFO
If needed, you can execute priorized import jobs by bypassing the Job Scheduler's queue. For that, according role capabilities are needed as well as cluster resources.
To priorize an import job when configuring it in the import job wizard, simply mark the check box "Bypass Internal Job Queue". The import job will be executed right after finishing the import job wizard.