Azure Databricks
- Juliane Wetzel
Owned by Juliane Wetzel
INFO
Azure Databricks is an Apache Spark based analytics service with an interactive workspace that enables collaboration between data scientists, data engineers, and business analysts. Find more information here.
Prerequisites
Preparing Azure Databricks
INFO
Set up your cluster in the Databricks workspace on https://portal.azure.com.
Uploading the Database Driver
INFO
Set up the database driver in the 'Admin' tab.
Configuring Azure Databricks as a Connection
To configure Azure Databricks as a connector:
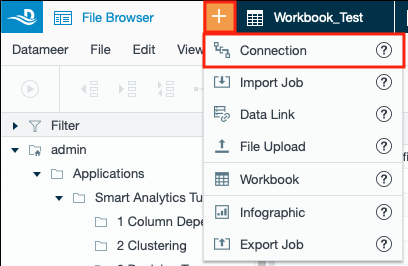
- Click the "+" button and select "Connection" or right-click in the File Browser and select "Create New" → "Connection". The "New Connection" tab appears in the menu bar.
 or
or 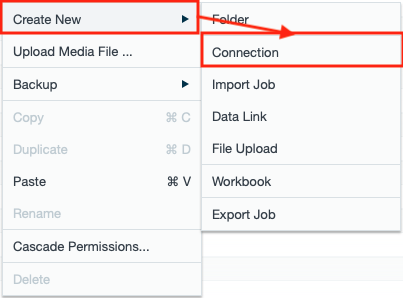
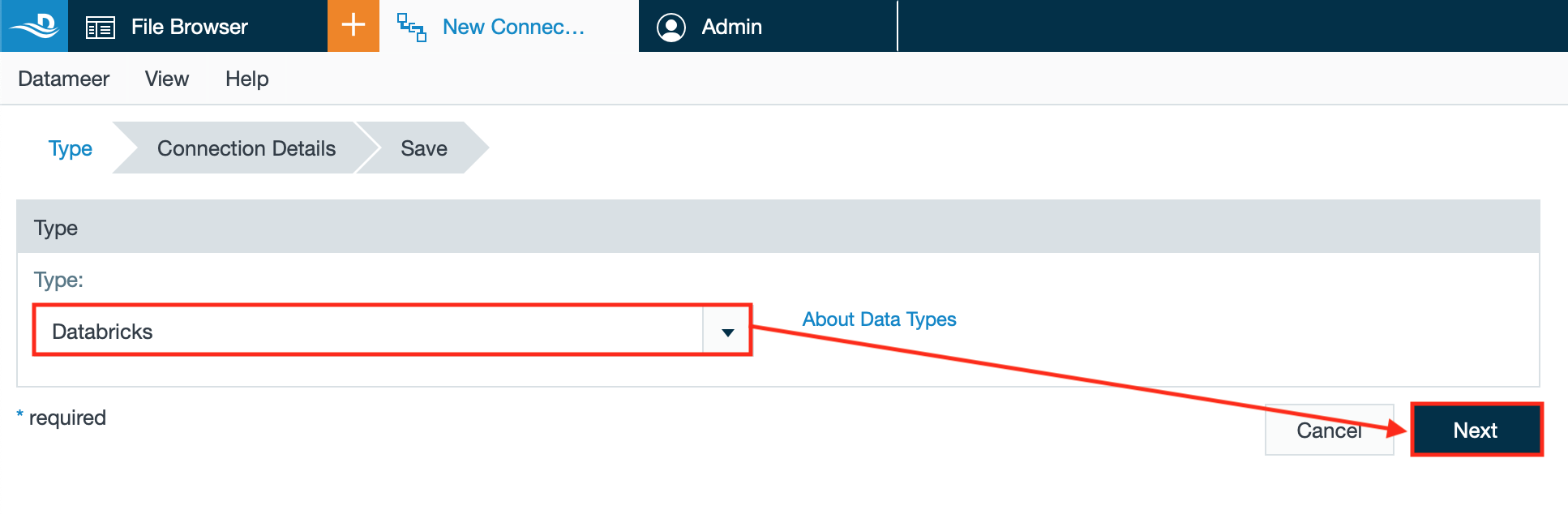
- Select "Databricks" from the drop-down and confirm with "Next". The type is displayed in the drop-down.
- Enter the connection string from the database driver.
INFO: End the connection string with ';UseNativeQuery=1'.
INFO: Note that the pattern must contain the expression 'token' as the 'UID' parameter and the '<personal-access-token>' as the 'PWD' parameter that you created both in Azure Databricks before.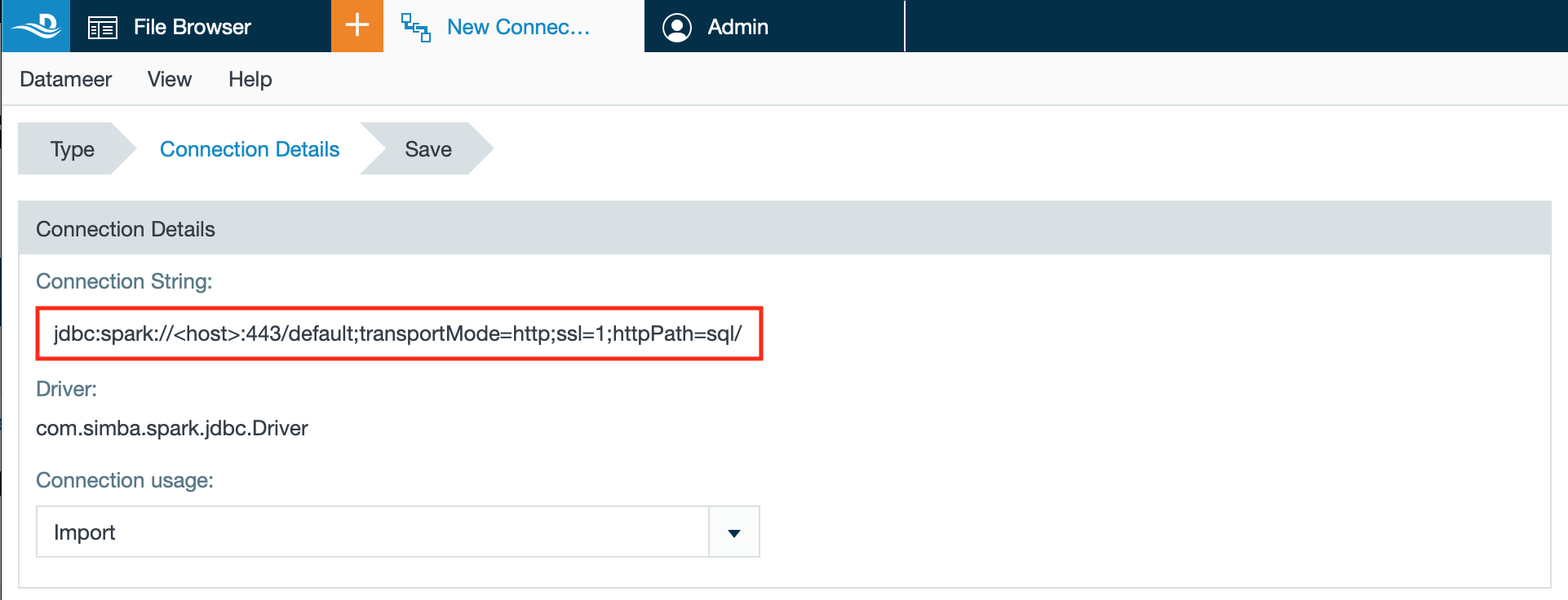
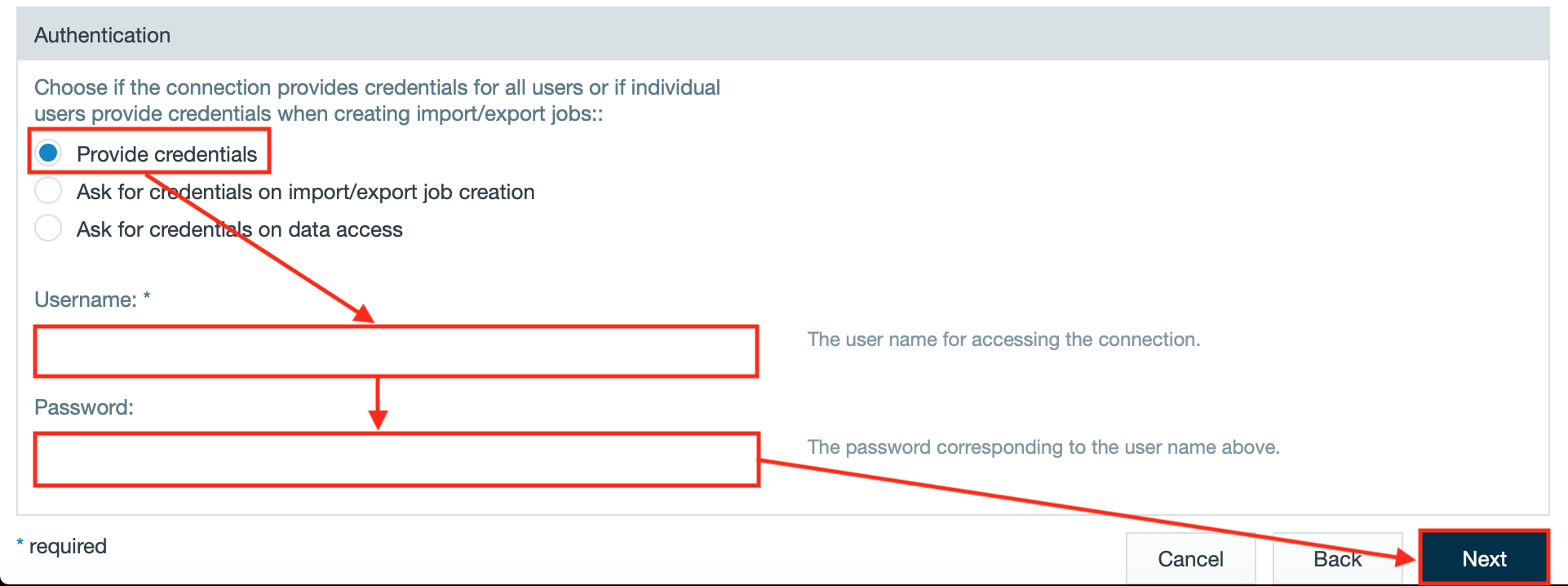
- Choose "Provide credentials", enter the username and password from the connection string and confirm with "Next". The 'Save Connection' tab opens.
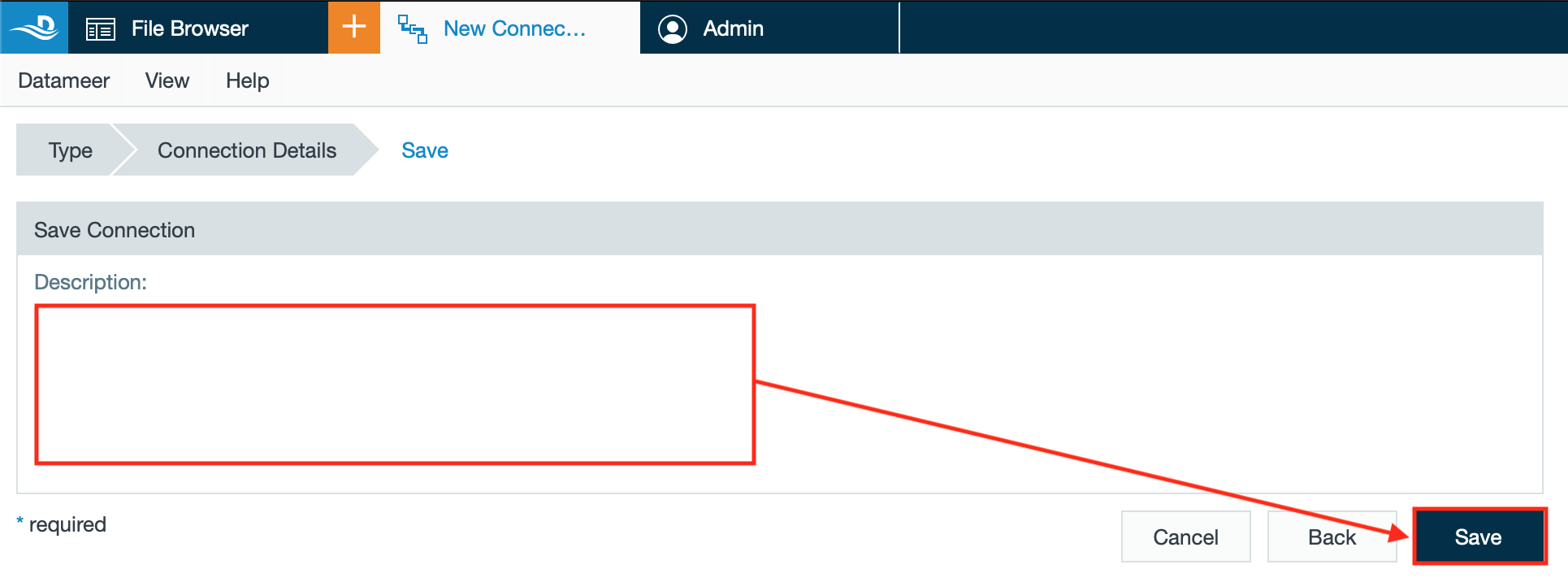
- If needed, enter a description and confirm with "Next". The 'Save Connection' dialog opens.
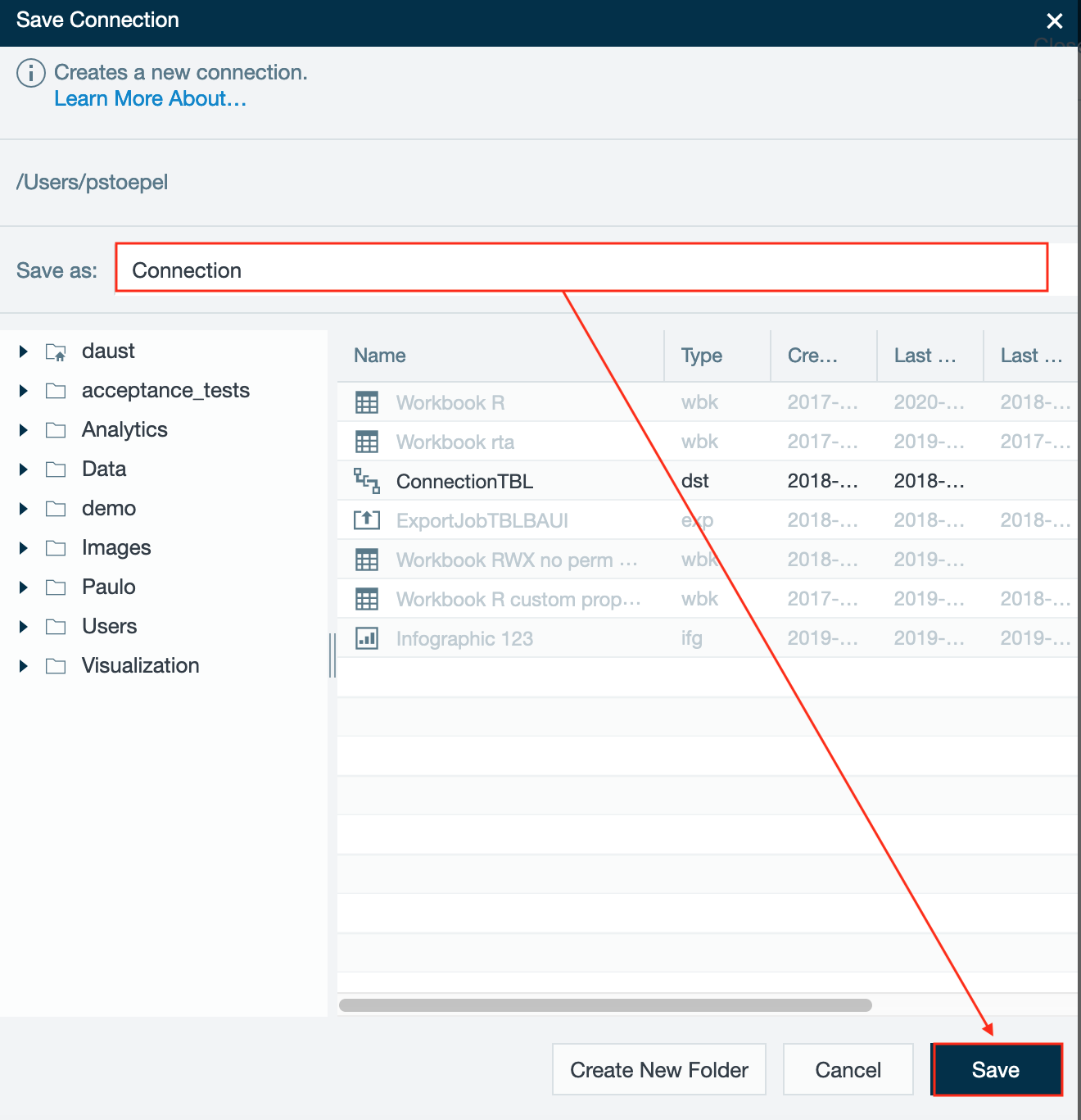
- Select the folder to save the connection, enter a name in "Save as" and confirm with "Save". The connection is saved. Configuring Azure Databricks as a JDBC connection is finished.
Importing Data with a Azure Databricks Connector
INFO
Find how to import from Azure Databricks here.