Import Functionality Updates
Improvements to Hive-Plugin
Datameer 7.5 includes several updates to UI performance, the Import Job Wizard, the Hive Data Link Wizard, and behavior of partitioned and non-partitioned Hive tables. Performance improvements include reduced execution time and new Production Mode. See HiveServer2, Exporting to HiveServer1 and HiveServer2, and Hive for related documentation.
As of Datameer 7.5, Datameer Classic data field type mapping is removed and only Hive specific mapping is performed, where Datameer BigDecimal maps to Hive Decimal and Datameer Date maps to Hive TimeStamp.
Note that Datameer support for Hive Metastore (Hive Server1) is being deprecated in favor of HiveServer2, effective in a future Datameer minor release.
It is strongly recommended that the appropriate configuration changes be introduced as soon as possible.
Exporting into non-partitioned Hive tables
With Datameer v7.5 we use the same functionality for writing table data of partitioned and unpartitioned tables. Partitioned and unpartitioned tables both use a validation before a record is written, but this can be disabled with the property hive.server2.export.record.validation=false. For both partitioned and unpartitioned the same write mechanism supports correct output format. For unpartitioned tables with mode RECREATE, the original table definition is used to recreate the table and only columns name and type are replaced by the export sheet definition.
Exporting to partitioned Hive table automatically sorts records
Datameer now automatically sorts data via partitioned Hive columns before an export job runs, without manual intervention.
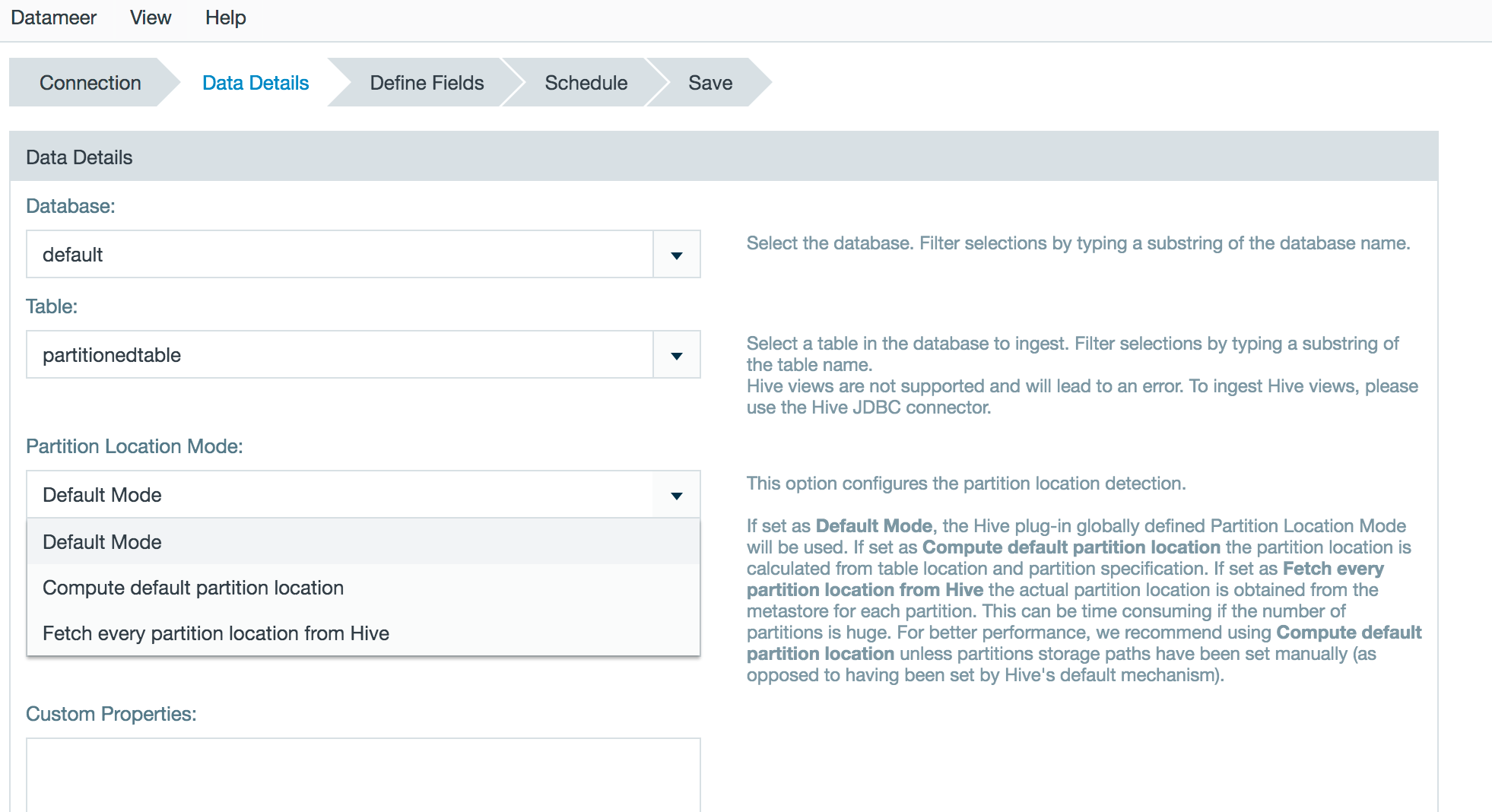
Property to compute Hive partition location within Datameer
Datameer is able to compute the partition location while importing data from a partitioned Hive table without needing to fetch it from the HiveServer 2. This improves performance if the default partition location pattern is used. The setting can be made globally within the plugin configuration page, and the default value can be overwritten with the Import Job or Data Link wizard.
Merging fixes and improvements from version 7.5 down to 7.4
Bug fixes, new features, and improvements from Datameer 7.5 are incorporated in v7.4, including:
- same mapping mechanics, validation, and export behavior for partitioned and unpartitioned tables
- fix for data serialization for unpartitioned table
- correct column type mapping for specific mode for unpartitioned tables mappings
- mapping now fully tested based on mapping rules so wrong mapping will result in a failed export
- record values now validated before writing bad records dropped
- record value validation can be disabled with custom hadoop property setting
- errors for mapping and validation are logged
Export data mapping changes
Direct conversion to Hive values - "implicit mapping" - is implemented, where Datameer creates table schema for new tables and for exports into an existing table, performs type mapping validation to make sure records match the expected table column structure.
Support for Hive import/export on AWS EMR 5.24
As of version 7.5, Datameer supports Hive within Amazon EMR 5.24. For specific information about Hive integration please contact your Datameer service team member.
Hive Metastore server deprecation and configurable warning
Datameer support for Hive Metastore (Hive Server1) is being deprecated in favor of HiveServer2, effective in one of the next Datameer minor releases. It is strongly recommended that the appropriate configuration changes be introduced as soon as possible. Dialogs where use of a Hive connection is an option will display a warning to this effect.
If a Hive Server1 connection is used for run processing, the final job status will be COMPLETED_WITH_WARNINGS, even if there were no processing errors or other issues with execution. This is intentional and does not require escalation to Datameer support. Rather, it is intended to alert you that important functionality will be removed in an upcoming version. See related details on the Hive page.
Google BigQuery Connector
Datameer 7.5 supports imports from Google BigQuery serverless SQL data warehouse for the cloud.
Parquet Import: Support for Advanced Data Types
Enabled support of Parquet files containing binary, fixed, int32 and int64 DECIMAL column types.
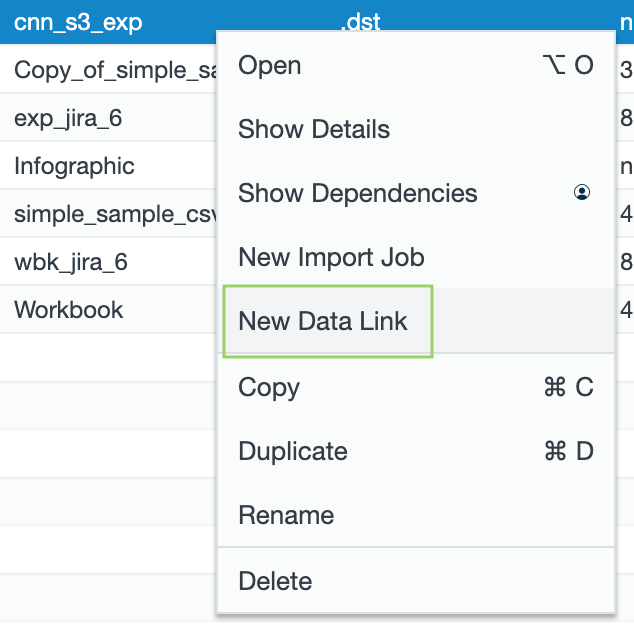
Context Menu Option "New Data Link"
You can now access the menu command "New Data Link" from the browser connection context menu.
Save & Migrate Added for Data Link and Import Job
If the partitioning of an existing import job is reconfigured, rather than re-fetching data from the source, Datameer performs a migration. The "Save & Migrate" button also performs a migration.
Export Functionality Updates
Tableau Hyper Format Export Support
Datameer supports exports to Tableau 10.5 or higher using the Tableau Hyper format.
Workbook Functionality Updates and Extensions
Pivot Table for Exploration and Preparation
Pivoting is a transform operation that converts columns to rows and also allows you to aggregate groupings and selections. Aggregation the ability to summarize large datasets across multiple custom-defined dimensions.
It can be used for simple group and aggregate operations, to group data by multiple columns, or for more complex situations where multiple variables are encoded as rows, with one or more column dimension columns and a single measure column that you want to convert to a column per variable. Different aggregations are available depending on the type of measure being used for the values of the pivoted columns: COUNT, ANY, MIN, MAX, SUM, AVG, VAR, STDEV, FIRST, and LAST.
Column Name Case-Sensitivity Support
As of release 7.5, Datameer supports case-sensitive column names so that, for example, Foo, foo, FoO, and fOO (etc.) will all be legal column names within a workbook or sheet.
Data Science Encoding for Workbook Columns
Datameer 7.5 includes the option to perform ordinal, 1-hot or binned encoding on column data. Once applied, encoding can be updated as needed until the desired results are achieved.
Workbook Production Mode
Workbook production mode accelerates performance by excluding sample generation and column statistics production to reduce resource usage. Production mode is intended for data pipelines that have been tested and refined to the point that a workbook can be scheduled and run without further modification.
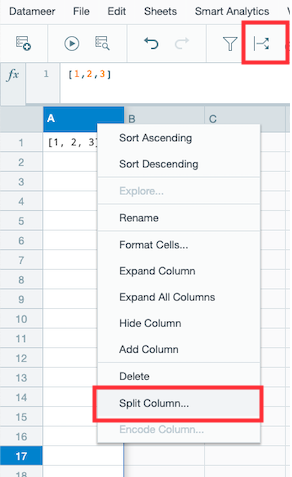
Split Column Transformation
Datameer 7.5 includes the option to split workbook string and list type column content by a selected delimiter.
Column Encoding
Column encoding provides the option to perform ordinal, 1-hot or binned encoding on column data, which assigns a unique numeric value to each categorical or continuous value. Once applied, encoding can be updated as needed until the desired results are achieved. Using Datameer to perform encoding provides a consistent view of prepared data, which is especially helpful for teams working together on model building and testing activities.
Workbook Data Access Permissions
You can use the File Browser to set permissions for import, export jobs, data links, and connections, and to set workbook permissions. You can also use related custom properties to determine whether or not reading workbook data requires permissions on the upstream data. Documentation in on the Behavior Change page under "Setting Access Permission Evaluation for Workbooks."
Datameer Configuration
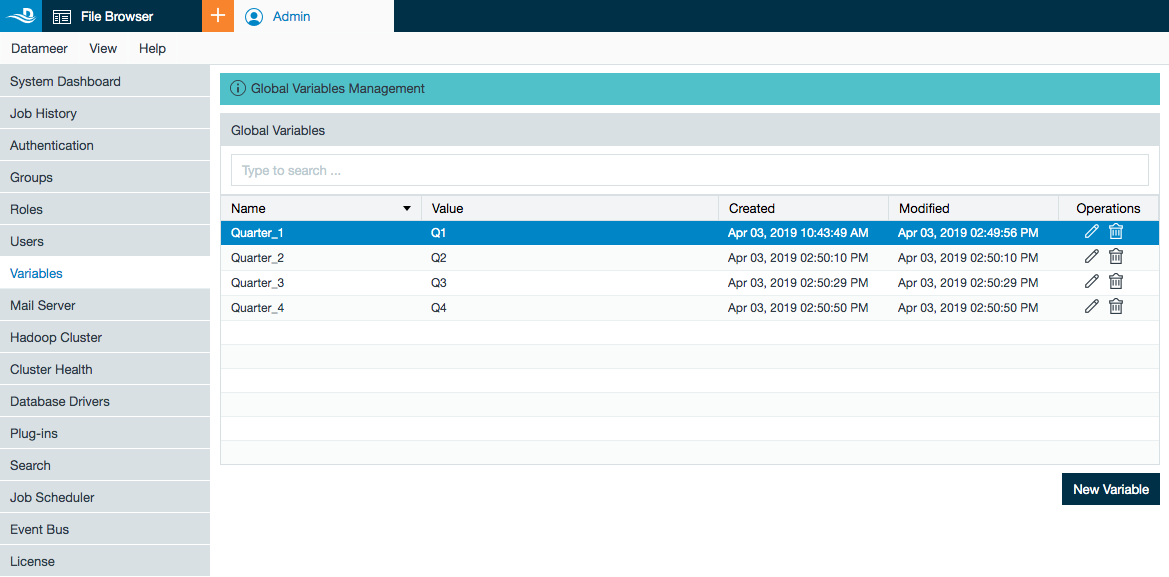
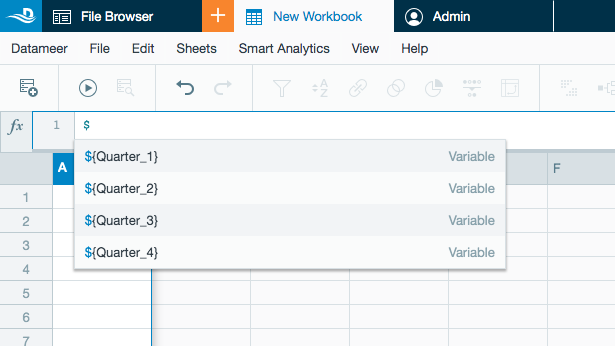
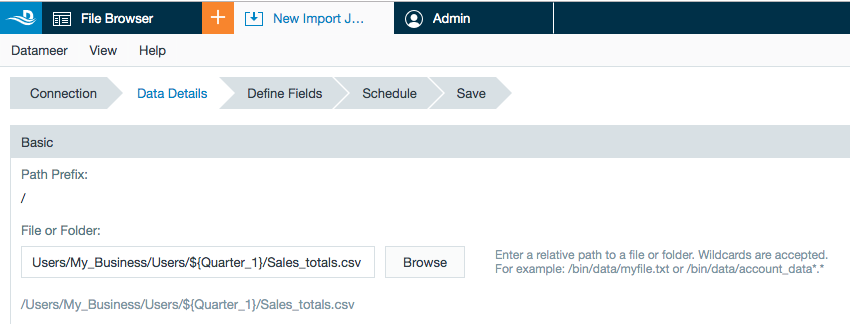
Datameer Global and Workbook Variables
Datameer has introduced global variables that can be used in both file paths and within your workbooks. Variables can be configured from the Datameer UI under the Admin tab or through the REST API.
Azure Data Lake Storage (ADLS) Gen1 as Private Data Store
Datameer can now use Azure Data Lake Storage (gen1) to store results.
Support for Amazon Corretto Open JDK
Datameer now supports Amazon Corretto 8 Open JDK, which is a free Java SE standard compatible implementation and may be used as an alternative to Oracle's JDK. See Supported Operating Systems and System Requirements.
New Rest Endpoint for Triggering Multiple Jobs in Sequence
New Rest API call added to trigger multiple jobs in sequence. See REST API Job Commands.
Allow Datameer Installation Rollbacks Within Set Number of Days
A new property delays data deletion after a Datameer upgrade can be used to assure that rollback is successful if it is needed. See How to Roll Back to a Previous Database Version and Adjusting for Rollback.
Custom Property "ErrorHandling Mode"
Default value of error handling can now be modified to better highlight processing errors and avoid cases when an issue that might cause a significant data inaccuracy could be ignored.
Network Proxy Servers for Datameer and Hadoop Cluster Outgoing HTTP(S) Connections
The S3 network proxy property sets the proxy for Snowflake, Redshift, S3 Native and S3 connectors for creating Data Links and Import Jobs. The S3 clusterjob property sets the outgoing connection for sending jobs to the cluster to fetch data from web services for S3, S3 Native, Snowflake, and Redshift. See Configuring Network Proxy page.
Job Timeout Parameter for Hadoop Jobs
New property das.job.hadoop-progress.timeout sets a duration, in seconds, after which a Datameer job will terminate with a "Timed out" status if there is no progress on the job.
Make changes to Enabling SSL for MySQL service page
The location of the file /<Datameer installation dir>/webapps/conductor/WEB-INF/classes/META-INF/persistence.xml has changed and is now a part of <Datameer installation dir>/webapps/conductor/WEB-INF/lib/dap-common-<version>.jar. The connection.url must be accordingly edited.
Additions to Supported Hadoop Distributions
Support for Hadoop CDH 6.1/6.2
Datameer 7.5 supports CDH 6.1 and 6.2 with configuration of certain custom properties. Older Hadoop distributions might no longer be supported as of Datameer v7.0, see Supported Hadoop Distributions.
Support for AWS EMR 5.24
See Support for Hive import/export on AWS EMR 5.24 above.